National Language Support (NLS) provides commands and library subroutines for a single worldwide system base. An internationalized system has no built-in assumptions or dependencies on language-specific or cultural-specific conventions. All locale information is obtained at program run time.
The following concepts are needed to understand the internationalization of programs:
ASCII is a code set containing 128 code points (0x00 through 0x7F). The ASCII character set contains control characters, punctuation marks, digits, and the uppercase and lowercase English alphabet. Several 8-bit code sets incorporate ASCII as a proper subset. However, throughout this document, ASCII refers to 7-bit-only code sets. To emphasize this, it is referred to as 7-bit ASCII. The 7-bit ASCII code set is a proper subset of all supported code sets and is referred to as the portable character set . For more information, see "Code Set Overview".
A single-byte encoding method is sufficient for representing the English character set because the number of characters is not large. To support larger alphabets, such as Japanese and Chinese, additional code sets containing multibyte encodings are necessary. All supported single-byte and multibyte code sets contain the single-byte ASCII character set. Therefore, programs that handle multibyte code sets must handle character encodings of one or more bytes.
Examples of single-byte code sets are the ISO 8859 family of code sets and the IBM-850 code set. Examples of multibyte character sets are the IBM-eucJP and the IBM-932 code sets. The single-byte code sets have at most 256 characters and the multibyte code sets have more than 256 (without any theoretical limit).
None of the supported code sets have bytes 0x00 through 0x3F in any byte of a multibyte character. This group of code points is called the unique code-point range. Furthermore, these code points always refer to the same characters as specified for 7-bit ASCII. This is a special property governing all supported code sets. ASCII Characters in the Unique Code-Point Range lists the characters in the unique code-point range.
Because the encoding for some characters requires more than one byte, a single character may be represented by one or several bytes when data is created in files or transferred between a computer and its I/O devices. This external representation of data is referred to as the file code or multibyte character code representation of a character.
For processing strings of such characters, it is more efficient to convert file codes into a uniform representation. This converted form is intended for internal processing of characters. This internal representation of data is referred to as the process code or wide character code representation of the character. An understanding of multibyte character and wide character codes is essential to the overall internationalization strategy.
A multibyte character code is an external representation of data, regardless of whether it is character input from a keyboard or a file on a disk. Within the same code set, the number of bytes that represent the multibyte code of a character can vary. You must use NLS functions for character processing to ensure code set independence .
For example, a code set may specify the following character encodings:
C = 0x43 * = 0x81 0x43 *C = 0x81 0x43 0x43
A program searching for C , not accounting for multibyte characters, finds the second byte of the *C string and assumes it found C when in fact it found the second byte of the * (asterisk) character.
The wide character code was developed so that multibyte characters could be processed more efficiently internally in the system. A multibyte character representation is converted into a uniform internal representation (wide character code) so that internally all characters have the same length. Using this internal form, character processing can be done in a code set-independent fashion. The wide character code refers to this internal representation of characters.
The wchar_t data type is used to represent the wide character code of a character. The size of the wchar_t data type is implementation-specific. It is a typedef definition and can be found in the ctype.h, stddef.h, and stdlib.h files. No program should assume a particular size for the wchar_t data type, enabling programs to run under implementations that use different sizes for the wchar_t data type.
On AIX 4.3, the wchar_t datatype is implemented as an unsigned short value (16 bits). The locale methods in AIX have been standardized such that in most locales, the value stored in the wchar_t for a particular character will always be its Unicode data value. For applications which are intended to run only on AIX, this allows certain applications handle the wchar_t datatype in a consistent fashion, even if the underlying codeset is unknown. All locales on AIX 4.3 will use Unicode for their wide character code values (process code), except the following:
Every character has several language-dependent attributes or properties. These properties are called class properties . For example, the lowercase letter a in U.S. English has the following properties:
Character class properties are specified by the LC_CTYPE category.
Character ordering or collation refers to the culture-specific ordering of characters. This ordering differs from that based on the ordinal value of a character in a code set. Collation-based ordering is dependent on the language. Character collation is specified by the LC_COLLATE category. The term collating element refers to one or more characters that have a collation value in a specific locale. The Spanish ll character is an example of a multicharacter collating element.
To sort the characters in any given language in the proper order, a weight is assigned to each character so they sort as expected. However, a character's sort value and code-point value are not necessarily related.
One set of weights is not sufficient to sort strings for all languages. For example, in the case of the German words b�ch and bane , if there is only one set of weights, and the weight of the letter a is less than that of � , then bane sorts before b�ch . However, the opposite result is correct. To satisfy the requirement of this example, two sets of weights, the primary and secondary weights, are given to each character in the language. In the case of the characters a and � , they have the same primary weights, but differ in their secondary weights. In the German locale, the secondary weight of a is less than that of � .
The sorting algorithm first compares the two strings based on the primary weights of each character. If the primary weight values are the same, the two strings are compared again based on their secondary weights. In this example, the primary weights of the first two characters ba and b� are the same, but the primary weights of the characters that follow (c and n , respectively) differ. As a result of this comparison, b�ch is sorted before bane .
Here, the secondary weights are not used to collate the strings. However, as in the case of the strings bach and b�ch , secondary weights must be used to get the proper order. When compared using primary weight values, these two strings are found to be equivalent. To break the tie, the secondary weights of a and � are used. Because the secondary weight of a is less than that of � , the string bach sorts before b�ch .
Characters having the same primary weights belong to the same equivalence class. In this example, the characters a and � are said to be members of the same equivalence class.
In string collation, each pair of strings is first compared based on primary weight. If the two strings are equal, they are compared again based on their secondary weights. If still equal, they are compared again based on tertiary weights up to the limit set by the COLL_WEIGHTS_MAX collating weight limit specified in the sys/limits.h file.
Code-set width refers to the maximum number of bytes required to represent a character as a file code. This information is specified by the LC_CTYPE category.
Code-set display width refers to the maximum number of columns required to display a character on a terminal. This information is specified by the LC_CTYPE category.
An internationalized program must process information correctly for different locations. For example, in the United States, the date format 9/6/1990 is interpreted to mean the sixth day of the ninth month of the year 1990. The United Kingdom interprets the same date format to mean the ninth day of the sixth month of the year 1990. The formatting of numerical and monetary data is also country specific, as in the case of the U.S. $ (dollar) and the U.K. � (pound).
A locale is defined by language-specific and cultural-specific conventions for processing information. All such information should be accessible to a program at run time so that the same program can display or process data differently for different countries. The process of providing a language interface to obtain and process this information into a database containing the locale-specific data is known as localization.
The setlocale subroutine establishes locale information. This subroutine uses the values of certain environment variables to initialize locale information contained in locale definition files. To deal with locale data in a logical manner, locale definition source files are divided into six categories defining specific aspects of the locale data.
A category is a group of language-specific and culture-specific data. For instance, data referring to date and time formatting, the names of the days of the week, and names of the months is grouped into the LC_TIME category. Each category uses a set of keywords that describe a particular aspect of a locale. The following standard categories can be defined in a locale definition source file:
| LC_COLLATE | Defines string-collation order information. |
| LC_CTYPE | Defines character classification, case conversion, and other character attributes. |
| LC_MESSAGES | Defines the format for affirmative and negative responses. |
| LC_MONETARY | Defines rules and symbols for formatting monetary numeric information. |
| LC_NUMERIC | Defines rules and symbols for formatting nonmonetary numeric information. |
| LC_TIME | Lists rules and symbols for formatting time and date information. |
Locale information consists of data from these six categories. Each locale is described by a locale definition file. These files are named by the language, territory and code set information they describe. The format for naming a locale definition file is:
language[_territory][.codeset][@modifier]
For example, the locale for the Danish language spoken in Denmark using the ISO8859-1 code set is da_DK.ISO8859-1 . The da stands for the Danish language and the DK stands for Denmark. The short form of da_DK is sufficient to indicate this locale. The same language and territory using the IBM-850 code set is indicated by either Da_DK.IBM-850 or Da_DK for short.
This locale refers to the ANSI C or POSIX-defined standard for the locale inherited by all processes at startup time. The C or POSIX locale assumes the 7-bit ASCII character set and defines information for the six previous categories.
The Installation Default Locale
The installation default locale refers to the locale selected at system installation time as the systemwide locale. For example, a French user in Canada may define the default locale to be fr_CA.ISO8859-1 (fr for French, CA for Canada, and ISO8859-1 for the code set). Every process uses this locale unless the NLS environment variables are changed.
For localization, NLS uses the following environment variables:
The LC_COLLATE, LC_CTYPE, LC_MONETARY, LC_NUMERIC, LC_TIME, and LC_MESSAGES environment variables determine the current values for their respective categories.
The LC_ALL and LANG environment variables also determine the current locale.
The NLSPATH environment variable specifies a colon-separated list of directory names where the message catalog files are located. This environment variable is used by the Message Facility component of the NLS subsystem.
The LOCPATH environment variable specifies the directories where localization information such as locale database files, input method files, and iconv converters are located. This variable specifies a colon-separated list of directory names. The list is used for setting up the locale for a particular process.
Note: All setuid and setgid programs will ignore the LOCPATH environment variable.
The environment variables that affect locale information can be grouped into three priority classes:
| high | LC_ALL |
| medium | LC_COLLATE, LC_CTYPE, LC_MESSAGES, LC_MONETARY, LC_NUMERIC, LC_COLLATE |
| low | LANG |
When a locale is requested by the setlocale subroutine for a particular category or for all categories, the environment variable settings are queried by their priority level in the following manner:
The following table shows the current setting of the environment variables and the effect of calling setlocale( LC_ALL,"") . After the setlocale subroutine is called, the string sorting and character properties are done as in the German language, the monetary formatting is done as in the US conventions, the numeric, time formatting is done in Danish conventions, the date and time data formatting is done in the Danish conventions, and the user messages are displayed in the Danish language. The last column indicates the locale setting after setlocale( LC_ALL,"") is called.
| Environment Variable and Category Names | Value of Environment Variables | Value of Category After Call To setlocale( LC_ALL,"") |
| LC_COLLATE | de_DE | de_DE |
| LC_CTYPE | de_DE | de_DE |
| LC_MONETARY | en_US | en_US |
| LC_NUMERIC | (unset) | da_DK |
| LC_TIME | (unset) | da_DK |
| LC_MESSAGES | (unset) | da_DK |
| LC_ALL | (unset) | (not applicable) |
| LANG | da_DK | (not applicable) |
Multibyte subroutines process characters in file-code form. The names of these subroutines usually start with the prefix mb. However, some multibyte subroutines do not have this prefix. For example, the strcoll and strxfrm subroutines process characters in their multibyte form but do not have the mb prefix. The following standard C subroutines operate on bytes and can be used in handling multibyte data: strcmp, strcpy, strncmp, strncpy, strcat, and strncat . The standard C search subroutines strchr, strrchr, strpbrk, strcspn, strrchr, strspn, strstr, and strtok can be used in the following cases:
Wide character subroutines process characters in process-code form. Wide character subroutines usually start with a wc prefix. However, there are exceptions to this rule. For example, the wide character classification functions use an isw prefix. To determine if a subroutine is a wide character subroutine, check if the subroutine prototype defines characters as wchar_t data type or wchar_t data pointer, or else check whether the subroutine returns a wchar_t data type. There are some exceptions to this rule. For example, the wide character classification subroutines accept wint_t data type values.
An internationalized program may need to handle bidirectionality of text and character shaping.
Bidirectionality (BIDI) occurs when texts of different direction orientation appear together. For example, English text is read from left to right. Hebrew text is read from right to left. If both English and Hebrew texts appear on the same line, the text is bidirectional.
Character shaping occurs when the shape of a character is dependent on its position in a line of text. In some languages, such as Arabic, characters have different shapes depending on their position in a string and on the surrounding characters.
For more information about bidirectionality and character shaping, see "Layout (Bidirectional Text and Character Shaping) Overview", "Character Shaping", and "Introducing Layout Library Subroutines".
The system needs certain information about code sets to communicate with the external environment. This information is hidden by the code set-independent library subroutines (NLS library). These subroutines pass information to the code set-dependent functions. Because NLS subroutines handle the necessary code set information, you do not need explicit knowledge of any code set when you write programs that process characters. This programming technique is called code set independence.
You can use the MB_CUR_MAX macro to determine the maximum number of bytes in a multibyte character for the code set in the current locale. The value of this macro is dependent on the current setting of the LC_CTYPE category. Because the locale can differ between processes, running the MB_CUR_MAX macro in different processes or at different times may produce different results. The MB_CUR_MAX macro is defined in the stdlib.h header file.
You can use the MB_LEN_MAX macro to determine the maximum number of bytes in any code set that is supported by the system. This macro is defined in the limits.h header file.
The _max_disp_width macro is operating-system-specific, and its use should be avoided in portable applications. If portability is not important, you can use the _max_disp_width macro to determine the maximum number of display columns required by a single character in the code set in the current locale . The value of this macro is dependent on the current setting of the LC_CTYPE category. If the value of this is 1 (one), all characters in the current code set require only one display column width on output.
When both MB_CUR_MAX and _max_disp_width are set to 1 (one), you can use the strlen subroutine to determine the display column width needed for a string. When MB_CUR_MAX is greater than one, use the wcswidth subroutine to find the display column width of the string.
The wcswidth and wcwidth wide character display width subroutines do not have corresponding multibyte functions. The wcswidth subroutine does not indicate how many characters can be displayed in the space available on a display. The wcwidth subroutine is useful for this purpose. This subroutine must be called repeatedly on a wide character string to find out how many characters can be displayed in the available positions on the display.
There is one exception to the statement: "No knowledge of the underlying code set can be assumed in a program." This exception arises due to the way the supported code sets are organized.
When a multibyte character string is searched for any character within the unique code-point range (for example, the . (period) character), it is not necessary to convert the string to process code form. It is sufficient to just look for that character (.) by examining each byte. This exception enables the kernel and utilities to search for the special characters . and / while parsing file names. If a program searches for any of the characters in the unique code-point range, the standard string functions that operate on bytes (such as strchr), should be used. ASCII Characters in the Unique Code-Point Range lists the characters in the unique code-point range.
Note: This exception is not a property that is applicable to all code sets. It should not be construed that this exception will remain valid in future releases.
POSIX.2 defines the fnmatch subroutine to be used for file name matching. An application can use the fnmatch subroutine to read a directory and apply a pattern against each entry. For example, the find utility can use the fnmatch subroutine. The pax utility can use the fnmatch subroutine to process its pattern operands. Applications that need to match strings in a similar fashion can use the fnmatch subroutine.
Note that the radix character, as obtained by nl_langinfo(RADIXCHAR), is a pointer to a string. It is possible that a locale may specify this as a multibyte character or as a string of characters. However, in AIX, a simplifying assumption is made that the RADIXCHAR is a single-byte character.
The programming model presented here highlights changes you need to make when an existing program is internationalized or when a new program is developed:
Note: Several subroutines based on process-code do not have corresponding subroutines based on file-code. Due to this asymmetry, it may be necessary to convert strings to process-code form and invoke the appropriate process-code subroutines.
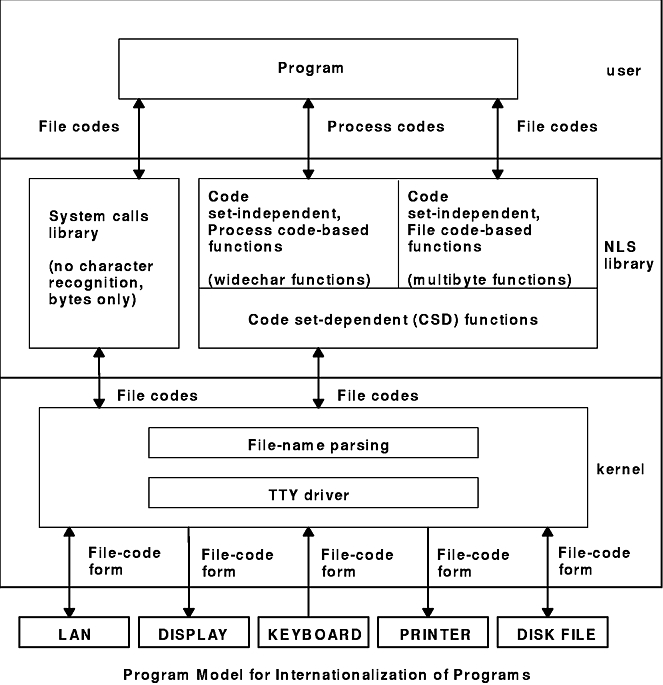
The Program Model for Internationalization of Programs diagram gives an overall view of the flow of user text data. The model indicates when the text data is in the multibyte character code (file-code) form and when it is in wide character code (process-code) form.
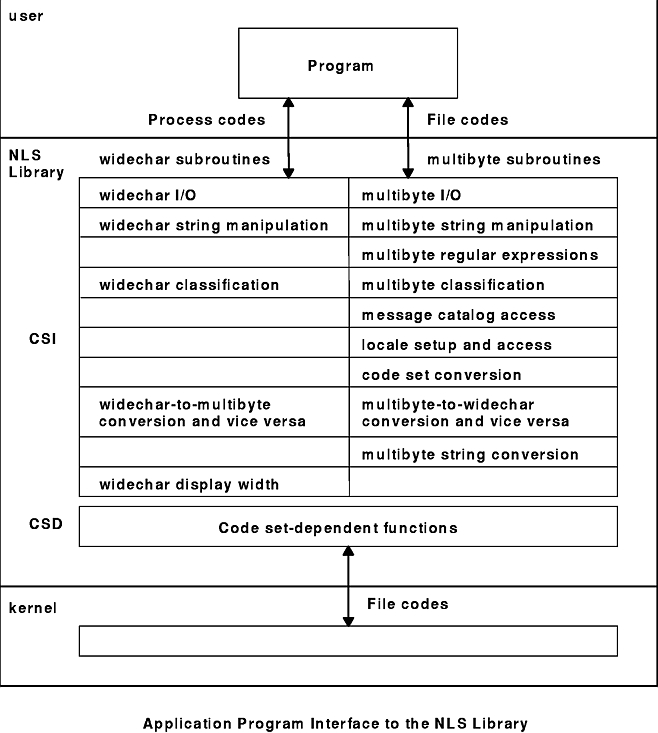
The Application Program Interface to the NLS Library diagram shows the process-code and file-code subroutine categories. Subroutines that support process codes may not have corresponding subroutines that support file codes. Also, subroutines that support file codes may not have corresponding subroutines that support process codes.
National Language Support Overview for Programming, Layout (Bidirectional Text and Character Shaping) Overview, Understanding Wide Character Code Subroutines, ASCII Characters in the Unique Code-Point Range.
National Language Support Overview for System Management and How to Change Your Locale in AIX Version 4.3 System Management Guide: Operating System and Devices.
Code Set Overview, Understanding Code Set Strategy in AIX Kernel Extensions and Device Support Programming Concepts.
Character Set Description (charmap) Source File Format, Locale Definition Source File Format.
For specific information about locale categories and their keywords, see the LC_COLLATE category, LC_CTYPE category, LC_MESSAGES category, LC_MONETARY category, LC_NUMERIC category, and LC_TIME category.
The setlocale subroutine, strcoll subroutine, strxfrm subroutine.
{kind=link}
{kind=link}