In an NFS network, the server is the primary target for tuning, but a few things can be tuned on the client as well.
Because biod and nfsd daemons handle one request at a time, and because NFS response time is often the largest component of overall response time, it is undesirable to have threads blocked for lack of a biod or nfsd daemon.
Note: Starting with AIX 4.2.1, there is a single nfsd daemon and a single biod daemon, each of which is multithreaded (multiple kernel threads within the process). Also, the number of threads is self-tuning in that it creates additional threads as needed. You can, however, tune the maximum number of nfsd threads by using the nfs_max_threads parameter of the nfso command. You can also tune the maximum number of biod threads per mount via the biod mount option.
The general considerations for configuring NFS daemons are as follows:
Determining the best numbers of nfsd and biod daemons is an iterative process. Guidelines can give you no more than a reasonable starting point.
The defaults are a good starting point for small systems, but should probably be increased for client systems with more than two users or servers with more than two clients. A few guidelines are as follows:
After you have arrived at an initial number of biod and nfsd daemons, or have changed one or the other, do the following:
To change the numbers of nfsd and biod daemons, use the chnfs command.
To change the number of nfsd daemons on a server to 10, both immediately and at each subsequent system boot, use the following:
# chnfs -n 10
To change the number of biod daemons on a client to 8 temporarily, with no permanent change (that is, the change happens now but is lost at the next system boot), use the following:
# chnfs -N -b 8
To change both the number of biod daemons and the number of nfsd daemons on a system to 9, with the change delayed until the next system boot, run the following command:
# chnfs -I -b 9 -n 9
Increasing the number of biod daemons on the client worsens server performance because it allows the client to send more request at once, further loading the network and the server. In extreme cases of a client overrunning the server, it may be necessary to reduce the client to one biod daemon, as follows:
# stopsrc -s biod
This leaves the client with the kernel process biod still running.
One of the choices you make when configuring NFS-mounted directories is whether the mounts will be hard (-o hard) or soft (-o soft). When, after a successful mount, an access to a soft-mounted directory encounters an error (typically, a timeout), the error is immediately reported to the program that requested the remote access. When an access to a hard-mounted directory encounters an error, NFS retries the operation.
A persistent error accessing a hard-mounted directory can escalate into a perceived performance problem because the default number of retries (1000) and the default timeout value (0.7 second), combined with an algorithm that increases the timeout value for successive retries, mean that NFS continues to try to complete the operation.
It is technically possible to reduce the number of retries, or increase the timeout value, or both, using options of the mount command. Unfortunately, changing these values sufficiently to remove the perceived performance problem might lead to unnecessary reported hard errors. Instead, use the intr option to mount the hard-mounted directories, which allows the user to interrupt from the keyboard a process that is in a retry loop.
Although soft-mounting the directories causes the error to be detected sooner, it runs a serious risk of data corruption. In general, read/write directories should be hard-mounted.
The mount command provides some NFS-tuning options that are often ignored or used incorrectly because of a lack of understanding of their use.
Before you start adjusting mount options, make certain that you know what you are trying to achieve with respect to packet delivery and packet turnaround on the server or network. You would use most of the NFS-specific mount options if your goal is to decrease the load on the NFS server, or to work around network problems.
The NFS performance-specific mount options are all specified as a list entry on the -o option for the mount command. Separate the options for the -o option on the command line only by a comma, not by a comma and a space.
The most useful options are those for changing the read and write size values. These options define the maximum sizes of each RPC for read and write. Often, the rsize and wsize options of the mount command are decreased to decrease the read/write packet that is sent to the server. There can be two reasons why you might want to do this:
Reducing the rsize and wsize may improve the NFS performance in a congested network by sending shorter package trains for each NFS request. But a side effect is that more packets are needed to send data across the network, increasing total network traffic, as well as CPU utilization on both the server and client.
If your NFS file system is mounted across a high-speed network, such as the SP Switch, then larger read and write packet sizes would enhance NFS file system performance. With NFS Version 3, rsize and wsize can be set as high as 65536. The default is 32768. With NFS Version 2, the largest that rsize and wsize can be is 8192, which is also the default.
If your workload does not use the NFS access control list (ACL) support on a mounted file system, you can reduce the workload on both client and server to some extent by specifying the noacl option. This can be done as follows:
options=noacl
Set this option as part of the client's /etc/filesystems stanza for that file system.
Another mount command option to look at is retrans, which sets the number of NFS transmissions (the default is 3).
Related to the hard-versus-soft mount question is the question of the appropriate timeout duration for a given network configuration. If the server is heavily loaded, is separated from the client by one or more bridges or gateways, or is connected to the client by a WAN, the default timeout criterion may be unrealistic. If so, both server and client are burdened with unnecessary retransmits. For example, if the following command:
# nfsstat -c
reports a significant number (greater 5 percent of the total) of both timeouts and badxids, you could increase the timeo parameter with the following SMIT fast path:
# smitty chnfsmnt
Identify the directory you want to change, and enter a new value on the line NFS TIMEOUT. In tenths of a second.
The default time is 0.7 second (timeo=7), but this value is manipulated in the NFS kernel extension depending on the type of call. For read calls, for instance, the value is doubled to 1.4 seconds.
To achieve control over the timeo value for operating system version 4 clients, you must set the nfs_dynamic_retrans option of the nfso command to 0. There are two directions in which you can change the timeo value, and in any given case, there is only one right way to change it. The correct way, making the timeouts longer or shorter, depends on why the packets are not arriving in the allotted time.
If the packet is only late and does finally arrive, then you may want to make the timeo variable longer to give the reply a chance to return before the request is retransmitted.
However, if the packet has been dropped and will never arrive at the client, then any time spent waiting for the reply is wasted time, and you want to make the timeo shorter.
One way to estimate which option to take is to look at a client's nfsstat -cr output and see if the client is reporting lots of badxid counts. A badxid value means that an RPC client received an RPC call reply that was for a different call than the one it was expecting. Generally, this means that the client received a duplicate reply for a previously retransmitted call. Packets are thus arriving late and the timeo should be lengthened.
Also, if you have a network analyzer available, you can apply it to determine which of the two situations is occurring. Lacking that, you can try setting the timeo option higher and lower and see what gives better overall performance. In some cases, there is no consistent behavior. Your best option then is to track down the actual cause of the packet delays/drops and fix the real problem; that is, server or network/network device.
For LAN-to-LAN traffic through a bridge, try 50 (tenths of seconds). For WAN connections, try 200. Check the NFS statistics again after waiting at least one day. If the statistics still indicate excessive retransmits, increase timeo by 50 percent and try again. You will also want to examine the server workload and the loads on the intervening bridges and gateways to see if any element is being saturated by other traffic.
Given that dropped packets are detected on an NFS client, the real challenge is to find out where they are being lost. Packets can be dropped at the client, the server, and somewhere on the network.
Packets are rarely dropped by a client. Because each client RPC call is self-pacing, that is, each call must get a reply before going on, there is little opportunity for overrunning system resources. The most stressful operation is probably reading, where there is a potential for 1 MB+/sec of data flowing into the machine. While the data volume can be high, the actual number of simultaneous RPC calls is fairly small and each biod daemon has its own space allocated for the reply. Thus, it is very unusual for a client to drop packets.
Packets are more commonly dropped either by the network or by the server.
Two situations exist where servers will drop packets under heavy loads:
When an NFS server is responding to a very large number of requests, the server will sometimes overrun the interface driver output queue. You can observe this by looking at the statistics that are reported by the netstat -i command. Examine the columns marked Oerrs and look for any counts. Each Oerrs is a dropped packet. This is easily tuned by increasing the problem device driver's transmit queue size. The idea behind configurable queues is that you do not want to make the transmit queue too long, because of latencies incurred in processing the queue. But because NFS maintains the same port and XID for the call, a second call can be satisfied by the response to the first call's reply. Additionally, queue-handling latencies are far less than UDP retransmit latencies incurred by NFS if the packet is dropped.
The second common place where a server will drop packets is the UDP socket buffer. Dropped packets here are counted by the UDP layer and the statistics can be seen by using the netstat -p udp command. Examine the statistics marked UDP: for the socket buffer overflows statistic.
NFS packets will usually be dropped at the socket buffer only when a server has a lot of NFS write traffic. The NFS server uses a UDP socket attached to NFS port 2049 and all incoming data is buffered on that UDP port. The default size of this buffer is 60,000 bytes. You can divide that number by the size of the default NFS write packet (8192) to find that it will take only eight simultaneous write packets to overflow that buffer. This overflow could occur with just two NFS clients (with the default configurations).
In this situation there is either high volume or high burst traffic on the socket.
Each of the two situations is handled differently.
You might see cases where the server has been tuned and no dropped packets are arriving for either the socket buffer or the driver Oerrs, but clients are still experiencing timeouts and retransmits. Again, this is a two-case scenario. If the server is heavily loaded, it may be that the server is just overloaded and the backlog of work for nfsd daemons on the server is resulting in response times beyond the default timeout set on the client. See NFS Tuning Checklist for hints on how to determine if this is the problem. The other possibility, and the most likely problem if the server is known to be otherwise idle, is that packets are being dropped on the network.
If there are no socket buffer overflows or Oerrs on the server, the client is getting lots of timeouts and retransmits and the server is known to be idle, then packets are most likely being dropped on the network. What is meant by when network is mentioned? It means a large variety of things including media and network devices such as routers, bridges, concentrators, and the whole range of things that can implement a transport for packets between the client and server.
Anytime a server is not overloaded and is not dropping packets, but NFS performance is bad, assume that packets are being dropped on the network. Much effort can be expended proving this and finding exactly how the network is dropping the packets. The easiest way of determining the problem depends mostly on the physical proximity involved and resources available.
Sometimes the server and client are in close enough proximity to be direct-connected, bypassing the larger network segments that may be causing problems. Obviously, if this is done and the problem is resolved, then the machines themselves can be eliminated as the problem. More often, however, it is not possible to wire up a direct connection, and the problem must be tracked down in place.
NFS maintains a cache on each client system of the attributes of recently accessed directories and files. Five parameters that can be set in the /etc/filesystems file control how long a given entry is kept in the cache. They are as follows:
Each time the file or directory is updated, its removal is postponed for at least acregmin or acdirmin seconds. If this is the second or subsequent update, the entry is kept at least as long as the interval between the last two updates, but not more than acregmax or acdirmax seconds.
NFS does not have a data-caching function, but the Virtual Memory Manager (VMM) caches pages of NFS data just as it caches pages of disk data. If a system is essentially a dedicated NFS server, it may be appropriate to permit the VMM to use as much memory as necessary for data caching. This is accomplished by setting the maxperm parameter, which controls the maximum percentage of memory occupied by file pages, to 100 percent; for example:
# vmtune -P 100
The same technique could be used on NFS clients, but would only be appropriate if the clients were running workloads that had very little need for working-segment pages.
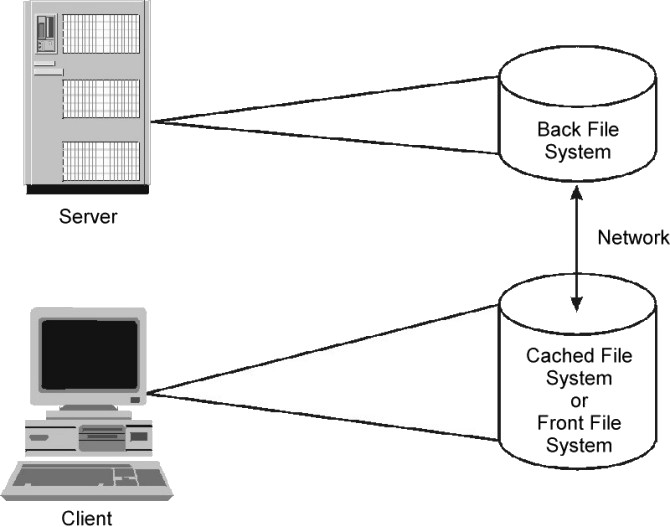
The Cache File System can be used to enhance performance of remote file systems or slow devices such as CD-ROM. When a file system is cached, the data read from the remote file system or CD-ROM is stored in a cache on the local system, thereby avoiding the use of the network and NFS server when the same data is accessed for the second time. CacheFS is designed as a layered file system; this means that CacheFS provides the ability to cache one file system (the NFS file system, also called the back-file system) on another (your local file system, also called the front-file system), as shown in the following figure:
Figure 10-3. Cache File System (CacheFS). This illustration show a client machine and a server that are connect by a network. The storage media on the server contains the back file system. The storage media on the client contains the cached file system or the front file system.
|
Note that in AIX 4.3, only NFS Version 2 and NFS Version 3 are supported as back-file systems, and JFS is the only supported front-file system.
CacheFS works as follows:
An example where CacheFS would be suitable is in a CAD environment where master-copies of drawing components can be held on the server and cached-copies on the client workstation when in use.
CacheFS does not allow reads and writes on files that are 2 GB or larger in size.
Because NFS data is cached on the local disk once it is read from the server, read requests to the NFS file system can be satisfied much faster than if the data had to be retrieved over the net again. Depending on the memory size and usage of the client, a small amount of data might be held and retrieved from memory, so that the benefits of cached data on the disk applies to a large amount of data that cannot be kept in memory. An additional benefit is that data on the disk cache will be held at system shutdown, whereas data cached in memory will have to be retrieved from the server again after the reboot.
Other potential NFS bottlenecks are a slow or busy network and a weak performing server with too many NFS clients to serve. Therefore, access from the client system to the server is likely to be slow. CacheFS will not prevent you from having to do the first read over the network and to access the server, but you can avoid reads over the network for further requests for the same data.
If more read requests can be satisfied from the client's local disk, the amount of NFS accesses to the server will decrease. This means that more clients can be served by the server; thus, the client per server ratio will increase.
Fewer read requests over the network will decrease your network load and, therefore, allow you to get some relief on very busy networks or space for other data transfers.
Not every application will benefit from CacheFS. Because CacheFS will only speed up read performance, mainly applications that have huge read requests for the same data over and over again will benefit from CacheFS. Large CAD applications will certainly benefit from CacheFS, because of the often very large models that they have to load for their calculations.
Performance tests showed that sequential reads from the CacheFS file system are 2.4 times to 3.4 times faster than reads from the NFS server's memory or disk.
CacheFS will not increase the write performance to NFS file systems. However, you have two write options to choose as parameters to the -o option of the mount command, when mounting a CacheFS. They will influence the subsequent read performance to the data. The write options are as follows:
Small reads might be kept in memory anyway (depending on your memory usage); so there is no benefit in also caching the data on the disk. Caching of random reads to different data blocks does not help, unless you will access the same data over and over again.
The initial read request still has to go to the server because only by the time a user attempts to access files that are part of the back file system will those files be placed in the cache. For the initial read request, you will see typical NFS speed. Only for subsequent accesses to the same data, you will see local JFS access performance.
The consistency of the cached data is only checked at intervals. Therefore, it is dangerous to cache data that is frequently changed. CacheFS should only be used for read-only or read-mostly data.
Write Performance over a cached NFS file system differs from NFS Version 2 to NFS Version 3. Performance tests have shown that:
CacheFS is not implemented by default or prompted at the time of the creation of an NFS file system.
Make sure to install fileset level 4.3.1.1 for enhanced CacheFS write performance over NFS in AIX 4.3.1.
The system administrator must specify explicitly which file systems are to be mounted in the cache as follows:
# cfsadmin -c -o parameters cache-directory
where parameters specify the resource parameters and cache-directory is the name of the directory where the cache should be created.
# mount -V cachefs -o backfstype=nfs,cachedir=/cache-directory remhost:/rem-directory local-mount-point
where rem-directory is the name of the remote host and file system where the data resides, and local-mount-point is the mount point on the client where the remote file system should be mounted.
Several parameters can be set at creation time, as follows:
NFS uses UDP or TCP to perform its network I/O. Ensure that you have applied the tuning techniques described in Tuning TCP and UDP Performance and Tuning mbuf Pool Performance. In particular, you should:
In the course of tuning UDP, you may find that the netstat -s command indicates a significant number of UDP socket buffer overflows. As with ordinary UDP tuning, increase the sb_max value. You also need to increase the value of nfs_socketsize, which specifies the size of the NFS socket buffer. Following is an example:
# no -o sb_max=131072 # nfso -o nfs_socketsize=130972
The previous example sequence sets sb_max to a value at least 100 bytes larger than the desired value of nfs_socketsize and sets nfs_socketsize to 130972.
Note: In AIX Version 4, the socketsize is set dynamically. Configurations using the no and nfso command must be repeated every time the machine is booted. Add them in the /etc/rc.net or /etc/rc.nfs file immediately before the nfsd daemons are started and after the biod daemons are started. The position is crucial.
NFS servers that experience high levels of write activity can benefit from configuring the journal logical volume on a separate physical volume from the data volumes. See Disk Preinstallation Guidelines for further details.
It is often necessary to achieve high parallelism on data access. Concurrent access to a single file system on a server by multiple clients or multiple client processes can result in throughput being bottlenecked on the disk I/O for a particular device. You can use the iostat command to evaluate disk loading.
For large NFS servers, the general strategy should be to divide evenly the disk I/O demand across as many disk and disk adapter devices as possible. This results in greater parallelism and the ability to run greater numbers of nfsd daemons. On a system where disk I/O has been well-distributed, it is possible to reach a point where CPU load becomes the limiting factor on the server's performance.
Many of the misuses of NFS occur because people do not realize that the files that they are accessing are at the other end of an expensive communication path. A few examples of this are as follows:
It can be argued that these are valid uses of the transparency provided by NFS. Perhaps this is so, but these uses do cost processor time and LAN bandwidth and degrade response time. When a system configuration involves NFS access as part of the standard pattern of operation, the configuration designers should be prepared to defend the consequent costs with offsetting technical or business advantages, such as:
Another type of application that should not be run across NFS file systems is an application that does hundreds of lockf() or flock() calls per second. On an NFS file system, all the lockf() or flock() calls (and other file locking calls) must go through the rpc.lockd daemon. This can severely degrade system performance because the lock daemon may not be able to handle thousands of lock requests per second.
Regardless of the client and server performance capacity, all operations involving NFS file locking will probably seem unreasonably slow. There are several technical reasons for this, but they are all driven by the fact that if a file is being locked, special considerations must be taken to ensure that the file is synchronously handled on both the read and write sides. This means there can be no caching of any file data at the client, including file attributes. All file operations go to a fully synchronous mode with no caching. Suspect that an application is doing network file locking if it is operating over NFS and shows unusually poor performance compared to other applications on the same client/server pair.
Following is a checklist that you can follow when tuning NFS:
The general method is to see if slowing down the client will increase the performance. The following methods can be tried independently:
Try running with just one biod daemon on the affected client. If performance increases, then something is being overrun either in the network or on the server. Run the stopsrc -s biod command to stop all the SRC biod daemons. It will leave one kernel process biod with which you can still run. See if it runs faster with just the one biod process. If it has no effect, restart the biod daemons with the startsrc -s biod command. If it runs faster, attempt to determine where the packets are being dropped when all daemons are running. Networks, network devices, slow server, overloaded server, or a poorly tuned server could all cause this problem.
This is probably the most common under-configuration error that affects NFS servers.
If there are any Oerrs, increase the transmit queues for the network device. This can be done with the machine running, but the interface must be detached before it is changed (rmdev -l). You cannot shut down the interface on a diskless machine, and you may not be at liberty to shut down the interface if other work is going on. In this case, you can use the chdev command to put the changes in ODM so they will be activated on the next boot. Start by doubling the current value for the queue length, and repeat the process (adding an additional 30 each time) until no Oerrs are reported. On SP2 systems where NFS is configured to run across the high-speed switch, Oerrs may occur on the switch when there has been a switch fault and the switch was temporarily unavailable. An error is counted towards Oerr for each attempt to send on the switch that fails. These errors cannot be eliminated.
Any counts that are very large indicate problems.
When using UDP, buffer overruns on the NFS server are another frequent under-configuration for NFS servers. TCP sockets can be similarly overrun on very busy machines. Tuning for both is similar, so this section discusses only UDP.
Run the netstat -s command and examine the UDP statistics for the socket buffer overflows statistic. If it is anything other than 0, you are probably overrunning the NFS UDP buffer. Be aware, however, that this is the UDP socket buffer drop count for the entire machine, and it may or may not be NFS packets that are being dropped. You can confirm that the counts are due to NFS by correlating between packet drop counts on the client using the nfsstat -cr command to socket buffer overruns on the server while executing an NFS write test.
Socket buffer overflows can happen on heavily stressed servers or on servers that are slow in relation to the client. Up to 10 socket buffer overflows are probably not a problem. Hundreds of overflows are. If this number continually goes up while you watch it, and NFS is having performance problems, NFS needs tuning.
Two factors can tune NFS socket buffer overruns. First try increasing the number of nfsd daemons that are being run on the server. If that does not solve the problem, you must adjust two kernel variables, sb_max(socket buffer max) and nfs_socketsize (the size of the NFS server socket buffer). Use the no command to increase sb_max. Use the nfso command to increase the nfs_socketsize variable.
The sb_max parameter must be set larger than nfs_socketsize. It is hard to suggest new values. The best values are the smallest ones that also make the netstat report 0 or just produce a few socket buffer overruns.
Remember, in AIX Version 4, the socket size is set dynamically. Configurations using the no and nfso command must be repeated every time the machine is booted. Add them in the /etc/rc.nfs file, right before the nfsd daemons are started and after the biod daemons are started. The position is crucial.
See if there are any requests for mbufs denied or delayed. If so, increase the number of mbufs available to the network. For more information about tuning to eliminate mbuf problems, see Tuning mbuf Pool Performance.
There have been rare cases where this has caused problems with machines. If there is a router or other hardware between the server and client, you can check its documentation to see if the interpacket delays can be configured. If so, try increasing the delay.
When packets are traversing two media with widely different speeds, the router might drop packets when taking them off the high speed net and trying to get them out on the slower net. This has been seen particularly when a router was trying to take packets from a server on FDDI and send them to a client on Ethernet. It could not send out the packets fast enough on Ethernet to keep up with the FDDI. The only solution is to try to slow down the volume of client requests, use smaller read/write sizes, and limit the number of biod daemons that can be used on a single file system.
Run the netstat -i command and check the MTU on the client and server. If they are different, try making them the same and see if the problem is eliminated. Also be aware that slow or wide area networks between the machines, routers, or bridges. may further fragment the packets to traverse these network segments. Attempt to determine the smallest MTU between source and destination, and change the rsize/wsize on the NFS mount to some number lower than that lowest-common-denominator MTU.
Use the traceroute command to look for unexpected routing hops or delays.
Run the errpt command and look for reports of network device or network media problems. Also look for any disk errors that might be affecting NFS server performance on exported file systems.