The internationalization of AIX is based on the assumption that all code sets can be divided into any number of character sets.
The following topics are covered in this section:
To understand code sets, it is necessary to first understand character sets. A character set is a collection of predefined characters based on the specific needs of one or more languages without regard to the encoding values used to represent the characters. The choice of which code set to use depends on the user's data processing requirements. A particular character set can be encoded using different encoding schemes. For example, the ASCII character set defines the set of characters found in the English language. The Japanese Industrial Standard (JIS) character set defines the set of characters used in the Japanese language. Both the English and Japanese character sets can be encoded using different code sets.
The ISO2022 standard defines a coded character set as a set of precise rules that defines a character set and the one-to-one relationship between each character and its bit pattern. A code set defines the bit patterns that the system uses to identify characters.
A code page is similar to a code set with the limitation that a code-page specification is based on a 16-column by 16-row matrix. The intersection of each column and row defines a coded character.
Consider the following when working with code sets:
The following code sets are supported:
A single-byte encoding method is sufficient for representing the English character set because the number of characters is not large. To support larger alphabets, such as Japanese and Chinese, additional code sets containing multibyte encodings are necessary. All supported single-byte and multibyte code sets contain the single-byte ASCII character set. Therefore, programs that handle multibyte code sets must handle character encodings of one or more bytes.
An example of a single-byte code set is the ISO 8859 family of code sets. Examples of multibyte character sets are the IBM-eucJP and the IBM-943 code sets. The single-byte code sets have at most 256 characters and the multibyte code sets have more than 256 (without any theoretical limit).
None of the supported code sets have bytes 0x00 through 0x3F in any byte of a multibyte character. This group of code points is called the unique code-point range. Furthermore, these code points always refer to the same characters as specified for 7-bit ASCII. This is a special property governing all supported code sets. ASCII Characters in the Unique Code-Point Range (ASCII Characters) lists the characters in the unique code-point range.
Because the encoding for some characters requires more than one byte, a single character may be represented by one or several bytes when data is created in files or transferred between a computer and its I/O devices. This external representation of data is referred to as the file code or multibyte character code representation of a character.
For processing strings of such characters, it is more efficient to convert file codes into a uniform representation. This converted form is intended for internal processing of characters. This internal representation of data is referred to as the process code or wide character code representation of the character. An understanding of multibyte character and wide character codes is essential to the overall internationalization strategy.
A multibyte character code is an external representation of data, regardless of whether it is character input from a keyboard or a file on a disk. Within the same code set, the number of bytes that represent the multibyte code of a character can vary. You must use NLS functions for character processing to ensure code set independence.
For example, a code set may specify the following character encodings:
C = 0x43 * = 0x81 0x43 *C = 0x81 0x43& 0x43
A program searching for C, not accounting for multibyte characters, finds the second byte of the *C string and assumes it found C when in fact it found the second byte of the * (asterisk) character.
The wide character code was developed so that multibyte characters could be processed more efficiently internally in the system. A multibyte character representation is converted into a uniform internal representation (wide character code) so that internally all characters have the same length. Using this internal form, character processing can be done in a code set-independent fashion. The wide character code refers to this internal representation of characters.
The wchar_t data type is used to represent the wide character code of a character. The size of the wchar_t data type is implementation-specific. It is a typedef definition and can be found in the ctype.h, stddef.h, and stdlib.h files. No program should assume a particular size for the wchar_t data type, enabling programs to run under implementations that use different sizes for the wchar_t data type.
On AIX 4.3, the wchar_t datatype is implemented as an unsigned short value (16 bits). On AIX 5.1 and later, the wchar_t datatype is 32-bit in the 64-bit environment and 16-bit in the 32-bit environment. . The locale methods have been standardized such that in most locales, the value stored in the wchar_t for a particular character will always be its Unicode data value. For applications which are intended to run only on AIX, this allows certain applications handle the wchar_t datatype in a consistent fashion, even if the underlying codeset is unknown. All locales use Unicode for their wide character code values (process code), except the following:
Do not assume that the char data type is either signed or unsigned. This is platform-specific. If the particular system that is used defines char to be signed, comparisons with full 8-bit quantity will yield incorrect results. As all the 8-bits are used in encoding a character, be sure to declare char as unsigned char wherever necessary. Also, note that if a signed char value is used to index an array, it may yield incorrect results. To make programs portable, define 8-bit characters as unsigned char.
Every character has several language-dependent attributes or properties. These properties are called class properties. For example, the lowercase letter a in U.S. English has the following properties:
Character class properties are specified by the LC_CTYPE category.
Character ordering or collation refers to the culture-specific ordering of characters. This ordering differs from that based on the ordinal value of a character in a code set. Collation-based ordering is dependent on the language. Character collation is specified by the LC_COLLATE category. The term collating element refers to one or more characters that have a collation value in a specific locale. The Spanish ll character is an example of a multicharacter collating element.
To sort the characters in any given language in the proper order, a weight is assigned to each character so that the characters sort as expected. However, a character's sort value and code-point value are not necessarily related.
One set of weights is not sufficient to sort strings for all languages. For example, in the case of the German words b<a-umlaut>ch and bane, if there is only one set of weights, and the weight of the letter a is less than that of <a-umlaut>, then bane sorts before b<a-umlaut>ch. However, the opposite result is correct. To satisfy the requirement of this example, two sets of weights, the Primary and Secondary Weights, are given to each character in the language. In the case of the characters a and <a-umlaut>, they have the same Primary Weights, but differ in their Secondary Weights. In the German locale, the Secondary Weight of a is less than that of <a-umlaut>.
The sorting algorithm first compares the two strings based on the Primary Weights of each character. If the Primary Weight values are the same, the two strings are compared again based on their Secondary Weights. In this example, the Primary Weights of the first two characters ba and b<a-umlaut> are the same, but the Primary Weights of the characters that follow (c and n, respectively) differ. As a result of this comparison, b<a-umlaut>ch is sorted before bane.
Here, the Secondary Weights are not used to collate the strings. However, as in the case of the strings bach and b<a-umlaut>ch, Secondary Weights must be used to get the proper order. When compared using Primary Weight values, these two strings are found to be equivalent. To break the tie, the Secondary Weights of a and <a-umlaut> are used. Because the Secondary Weight of a is less than that of <a-umlaut>, the string bach sorts before b<a-umlaut>ch.
Characters having the same Primary Weights belong to the same equivalence class. In this example, the characters a and <a-umlaut> are said to be members of the same equivalence class.
In string collation, each pair of strings is first compared based on Primary Weight. If the two strings are equal, they are compared again based on their Secondary Weights. If still equal, they are compared again based on Tertiary Weights up to the limit set by the COLL_WEIGHTS_MAX collating weight limit specified in the sys/limits.h file.
Code-set width refers to the maximum number of bytes required to represent a character as a file code. This information is specified by the LC_CTYPE category.
Code-set display width refers to the maximum number of columns required to display a character on a terminal. This information is specified by the LC_CTYPE category.
ASCII is a code set containing 128 code points (0x00 through 0x7F). The ASCII character set contains control characters, punctuation marks, digits, and the uppercase and lowercase English alphabet. Several 8-bit code sets incorporate ASCII as a proper subset. However, throughout this document, ASCII refers to 7-bit-only code sets. To emphasize this, it is referred to as 7-bit ASCII. The 7-bit ASCII code set is a proper subset of all supported code sets and is referred to as the portable character set. For more information, see Code Sets for National Language Support .
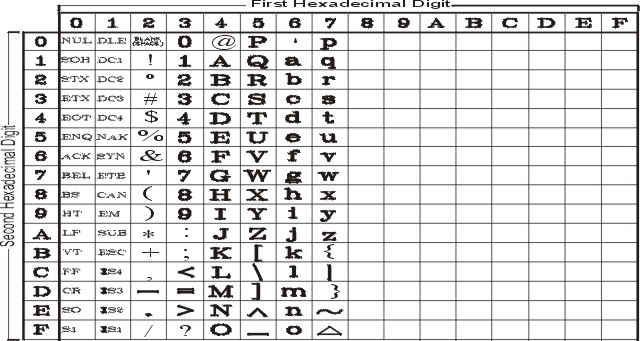
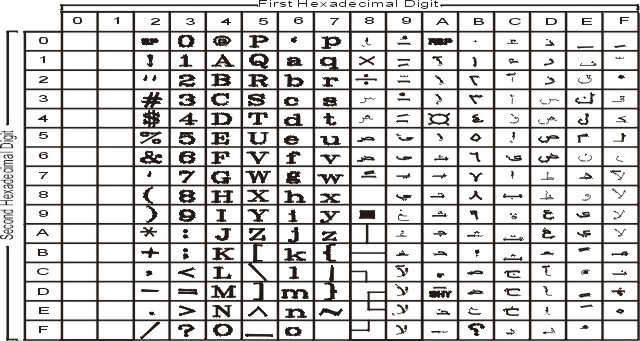
The following table lists the ASCII characters in the unique code-point range. These characters are in the range 0x00 through 0x3F.
| ASCII Characters in the Unique Code-Point Range | |||||
|---|---|---|---|---|---|
| Symbolic Name | Hex Value | Glyph | Symbolic Name | Hex Value | Glyph |
| nul | 00 |
|
space | 20 | blank |
| soh | 01 |
|
exclamation-mark | 21 | ! |
| stx | 02 |
|
quotation-mark | 22 | " |
| etx | 03 |
|
number-sign | 23 | # |
| eot | 04 |
|
dollar-sign | 24 | $ |
| enq | 05 |
|
percent | 25 | % |
| ack | 06 |
|
ampersand | 26 | & |
| alert | 07 |
|
apostrophe | 27 | ' |
| backspace | 08 |
|
left-parenthesis | 28 | ( |
| tab | 09 |
|
right-parenthesis | 29 | ) |
| newline | 0A |
|
asterisk | 2A | * |
| vertical-tab | 0B |
|
plus-sign | 2B | + |
| form-feed | 0C |
|
comma | 2C | , |
| carriage-return | 0D |
|
hyphen | 2D | - |
| so | 0E |
|
period | 2E | . |
| si | 0F |
|
slash | 2F | / |
| dle | 10 |
|
zero | 30 | 0 |
| dc1 | 11 |
|
one | 31 | 1 |
| dc2 | 12 |
|
two | 32 | 2 |
| dc3 | 13 |
|
three | 33 | 3 |
| dc4 | 14 |
|
four | 34 | 4 |
| nak | 15 |
|
five | 35 | 5 |
| syn | 16 |
|
six | 36 | 6 |
| etb | 17 |
|
seven | 37 | 7 |
| can | 18 |
|
eight | 38 | 8 |
| em | 19 |
|
nine | 39 | 9 |
| sub | 1A |
|
colon | 3A | : |
| esc | 1B |
|
semicolon | 3B | ; |
| is1 | 1C |
|
less-than | 3C | < |
| is2 | 1D |
|
equal-sign | 3D | = |
| is3 | 1E |
|
greater-than | 3E | > |
| is4 | 1F |
|
question-mark | 3F | ? |
The following table lists the 7-bit ASCII characters that are not in the unique code-point range. These characters are in the range 0x40 through 0x7F.
| Other ASCII Characters | |||||
|---|---|---|---|---|---|
| Symbolic Name | Hex Value | Glyph | Symbolic Name | Hex Value | Glyph |
| commercial-at | 40 | @ | grave-accent | 60 | ` |
| A | 41 | A | a | 61 | a |
| B | 42 | B | b | 62 | b |
| C | 43 | C | c | 63 | c |
| D | 44 | D | d | 64 | d |
| E | 45 | E | e | 65 | e |
| F | 46 | F | f | 66 | f |
| G | 47 | G | g | 67 | g |
| H | 48 | H | h | 68 | h |
| I | 49 | I | i | 69 | i |
| J | 4A | J | j | 6A | j |
| K | 4B | K | k | 6B | k |
| L | 4C | L | l | 6C | l |
| M | 4D | M | m | 6D | m |
| N | 4E | N | n | 6E | n |
| O | 4F | O | o | 6F | o |
| P | 50 | P | p | 70 | p |
| Q | 51 | Q | q | 71 | q |
| R | 52 | R | r | 72 | r |
| S | 53 | S | s | 73 | s |
| T | 54 | T | t | 74 | t |
| U | 55 | U | u | 75 | u |
| V | 56 | V | v | 76 | v |
| W | 57 | W | w | 77 | w |
| X | 58 | X | x | 78 | x |
| Y | 59 | Y | y | 79 | y |
| Z | 5A | Z | z | 7A | z |
| left-bracket | 5B | [ | left-brace | 7B | { |
| backslash | 5C | \ | vertical-line | 7C | | |
| right-bracket | 5D | ] | right-brace | 7D | } |
| circumflex | 5E | ^ | tilde | 7E | ~ |
| underscore | 5F | _ | del | 7F | |
Each locale in the system defines which code set it uses and how the characters within the code set are manipulated. Because multiple locales can be installed on the system, multiple code sets can be used by different users on the system. While the system can be configured with locales using different code sets, all system utilities assume that the system is running under a single code set.
Most commands have no knowledge of the underlying code set being used by the locale. The knowledge of code sets is hidden by the code set-independent library subroutines (NLS library), which pass information to the code set-dependent subroutines.
Because many programs rely on ASCII, all code sets include the 7-bit ASCII code set as a proper subset. Because the 7-bit ASCII code set is common to all supported code sets, its characters are sometimes referred to as the portable character set. The 7-bit ASCII code set is based on the ISO646 definition and contains the control characters, punctuation characters, digits (0-9), and the English alphabet in uppercase and lowercase.
Each code set is divided into the following principal areas:
| Graphic Left (GL) | Columns 0-7 |
| Graphic Right (GR) | Columns 8-F |
The first two columns of each code set are reserved by International Organization for Standardization (ISO) standards for control characters. The terms C0 and C1 are used to denote the control characters for the Graphic Left and Graphic Right areas, respectively.
The remaining six columns are used to encode graphic characters. Graphic characters are considered to be printable characters, while the control characters are used by devices and applications to indicate some special function.
Based on the ISO definition, a control character initiates, modifies, or stops a control operation. A control character is not a graphic character, but can have graphic representation in some instances. The control characters in the following table are present in all supported code sets and the encoded values of the control characters are consistent throughout the code sets.
| Name | Value | Description |
|---|---|---|
| NUL | 00 | Null |
| SOH | 01 | Start of header |
| STX | 02 | Start of text |
| ETX | 03 | End of text |
| EOT | 04 | End of transmission |
| ENQ | 05 | Enquiry |
| ACK | 06 | Acknowledge |
| BEL | 07 | Bell |
| BS | 08 | Backspace |
| HT | 09 | Horizontal tab |
| LF | 0A | Line feed |
| VT | 0B | Vertical tab |
| FF | 0C | Form feed |
| CR | 0D | Carrier return |
| SO | 0E | Shift Out |
| SI | 0F | Shift In |
| DLE | 10 | Data link escape |
| DC1 | 11 | Device control 1 |
| DC2 | 12 | Device control 2 |
| DC3 | 13 | Device control 3 |
| DC4 | 14 | Device control 4 |
| NAK | 15 | Not acknowledge |
| SYN | 16 | Synchrous idle |
| ETB | 17 | End of transmission block |
| CAN | 18 | Cancel |
| EM | 1 | End of media |
| SUB | 1A | Substitute character |
| ESC | 1B | Escape character |
| IS4 | 1C | Info Separator Four |
| IS3 | 1D | Info Separator Three |
| IS2 | 1E | Info Separator Two |
| IS1 | 1F | Info Separator One |
Each code set can be considered to be divided into one or more character sets, with each character having a unique coded value. The ISO standard reserves six columns for encoding characters and does not allow graphic characters to be encoded in the control character columns.
Code sets that use all 8 bits of a byte can support European, Middle Eastern, and other alphabetic languages. Such code sets are called single-byte code sets. Single-byte code sets have a limit of encoding 191 characters, not including control characters.
Languages that require more than 191 characters use a mixture of single-byte characters (8 bits) and multibyte characters (more than 8 bits). The system can support any number of bits to encode a character.
The code sets listed in the following topics are based on definitions set by the International Organization for Standardization (ISO).
The "ISO646-IRV code set" below defines the code set used for information processing based on a 7-bit encoding. The character set associated with this code set is derived from the ASCII characters.
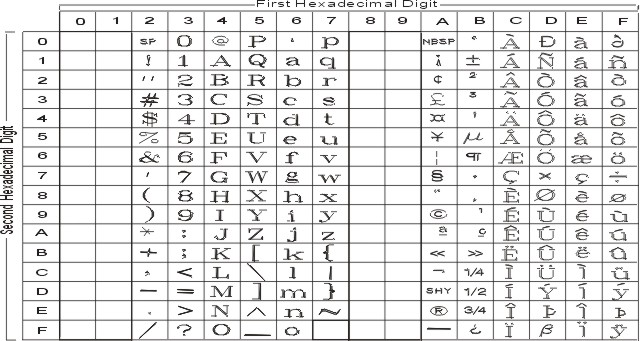
ISO8859 is a family of single-byte encodings based on and compatible with other ISO, American National Standards Institute (ANSI), and European Computer Manufacturer's Association (ECMA) code extension techniques. The ISO8859 encoding defines a family of code sets with each member containing its own unique character sets. The 7-bit ASCII code set is a proper subset of each of the code sets in the ISO8859 family.
While the ASCII code set defines an order for the English alphabet, the Graphic Right (GR) characters are not ordered according to any specific language. The locale defines the language-specific ordering.
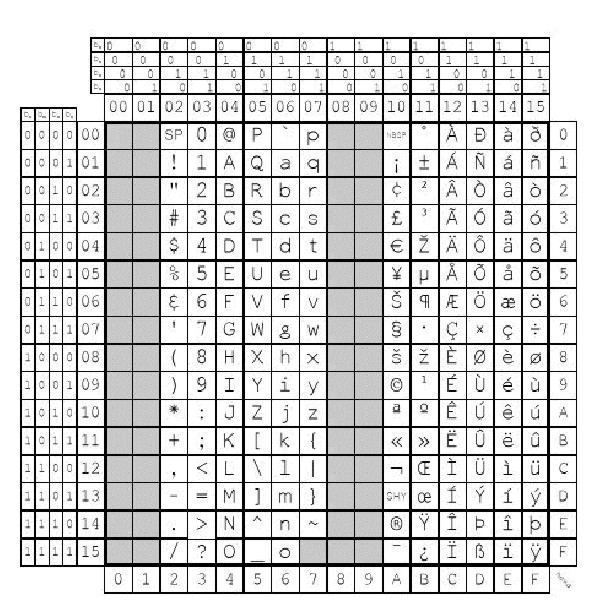
Each code set includes the ASCII character set plus its own unique character set. The ISO8859 encoding figure shows the ISO8859 general encoding scheme.
| Character Encoding | Code Point | Description | Count |
|---|---|---|---|
| 000xxxxx | 00-1F | Controls | 32 |
| 00100000 | 20 | Space | 1 |
| 0xxxxxxx | 21-7E | 7-bit | 94 |
| 01111111 | 7F | Delete | 1 |
| 100xxxxx | 80-9F | Controls | 32 |
| 10100000 | A0 | No-break Space | 1 |
| 1xxxxxxx | A1-F | 8-bit | 96 |
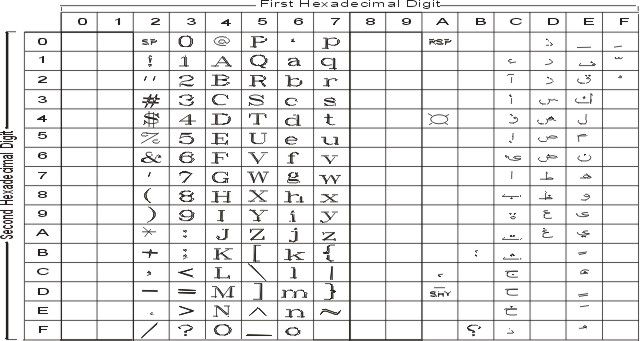
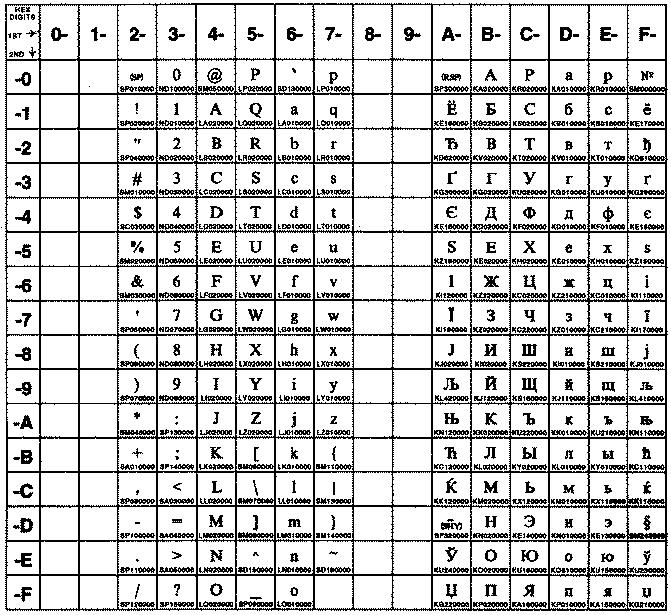
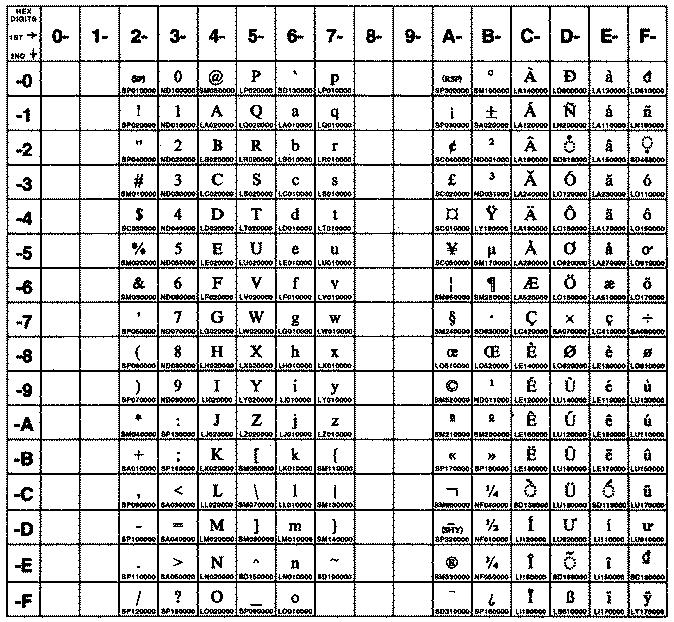
The following figure summarizes the available symbols and shows the layout of Code Set ISO8859-1. For a textual representation of this code set, see ISO8859-1.
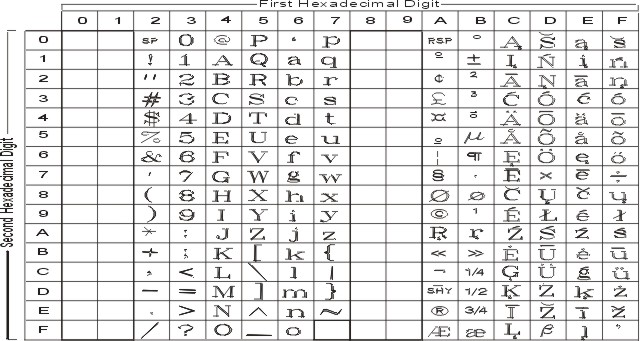
The following figure summarizes the available symbols and shows the layout of Code Set ISO8859-2. For a textual representation of this code set, see ISO8859-2.
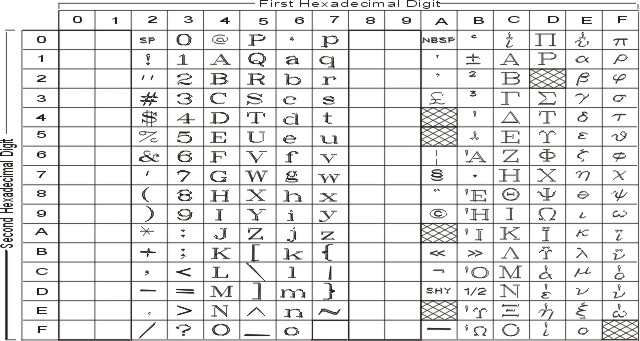
The following figure summarizes the available symbols and shows the layout of Code Set ISO8859-5. For a textual representation of this code set, see ISO8859-5.
The following figure summarizes the available symbols and shows the layout of Code Set ISO8859-6. For a textual representation of this code set, see ISO8859-6.
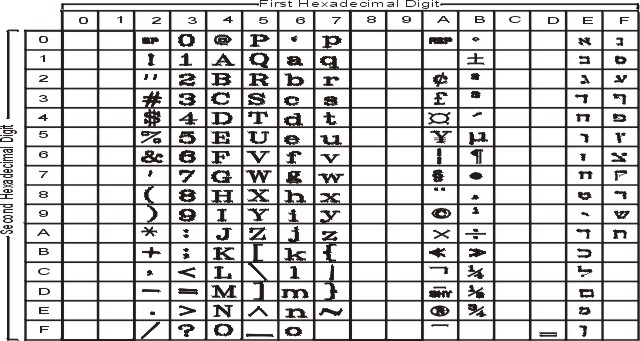
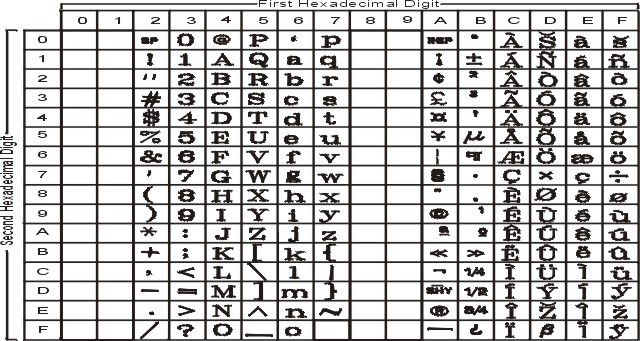
The following figure summarizes the available symbols and layout of Code Set ISO8859-7. This code set is made up of an ASCII character set plus its own unique character set. For a textual representation of this code set, see ISO8859-7.
The following figure summarizes the available symbols and shows the layout of Code Set ISO8859-8. For a textual representation of this code set, see ISO8859-8.
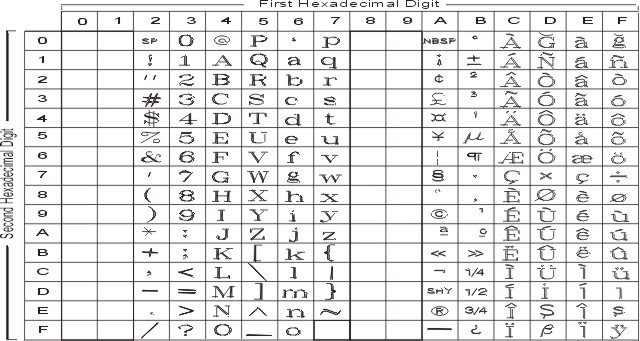
The following figure summarizes the available symbols and layout of Code Set ISO8859-9. This code set is made up of an ASCII character set plus its own unique character set. For a textual representation of this code set, see ISO8859-9.
The following figure summarizes the available symbols and shows the layout of Code Set ISO8859-15. For a textual representation of this code set, see ISO8859-15.
The EUC encoding scheme defines a set of encoding rules that can support one to four character sets. The encoding rules are based on the ISO2022 definition for the encoding of 7-bit and 8-bit data. The EUC encoding scheme uses control characters to identify some of the character sets. The following table shows the basic structure of all EUC encoding.
| EUC | Character Encoding |
|---|---|
| CS0 | 0xxxxxxx |
| CS1 | 1xxxxxxx
1xxxxxxx 1xxxxxxxx 1xxxxxxx 1xxxxxxxx 1xxxxxxx ... |
| CS2 | 10001110 1xxxxxxx
10001110 1xxxxxxx 1xxxxxxxx 10001110 1xxxxxxx 1xxxxxxxx 1xxxxxxxx ... |
| CS3 | 10001111 1xxxxxxx
10001111 1xxxxxxx 1xxxxxxxx 10001111 1xxxxxxx 1xxxxxxxx 1xxxxxxxx ... |
The term EUC denotes these general encoding rules. A code set based on EUC conforms to the EUC encoding rules but also identifies the specific character sets associated with the specific instances. For example, IBM-eucJP for Japanese refers to the encoding of the Japanese Industrial Standard characters according to the EUC encoding rules.
The first set (CS0) always contains an ISO646 character set. All of the other sets must have the most significant bit (MSB) set to 1 and can use any number of bytes to encode the characters. In addition, all characters within a set must have the following:
All characters in the third set (CS2) are always preceded with the control character SS2 (single-shift 2, 0x8e). Code sets that conform to EUC do not use the SS2 control character other than to identify the third set.
All characters in the fourth set (CS3) are always preceded with the control character SS3 (single-shift 3, 0x8f). Code sets that conform to EUC do not use the SS3 control character other than to identify the fourth set.
The EUC for Japanese is an encoding consisting of single-byte and multibyte characters. The encoding is based on ISO2022, Japanese Industrial Standard (JIS), and EUC definitions.
The IBM-eucJP code set consists of the following character sets:
| JISCII | JISX0201 Graphic Left character set |
| JISX0201.1976 | Katakana/Hiragana Graphic Right character set |
| JISX0208.1983 | Kanji level 1 and 2 character sets |
| IBM-udcJP | IBM-user definable characters |
The IBM-eucJP code set is also capable of supporting the following:
| JISX0212.1990 | Supplemental Kanji |
The IBM-eucJP code set is encoded as follows:
The EUC for the Simplified Chinese language is an encoding consisting of characters that contain 1 or 2 bytes. The EUC encoding is based on ISO2022, GB2312 as defined by the People's Republic of China, and multibyte character definitions unique to the manufacturer.
The current GB2312 defines 6,763 Simplified Chinese characters and 682 symbols. The IBM-eucCN is based upon a concept of one plane containing up to 94x94 characters. The encoding values of these characters range from 0xa1a1 to 0xfefe.
The GB2312 is mapped into the CS1 of EUC. Specifically, the IBM-eucCN consists of the following character sets:
| ISO0646-IRV | 7-bit ASCII character set, Graphic Left. |
| GB2312.1980 | Contains 7445 characters. It occupies positions 0xa1a1 to 0xfedf (some user-defined characters scattered in 0xa1a1 to 0xfedf). |
| IBM-udcCN | Scattered in GB. It occupies positions Oxa1a1 to Oxfedf. The actual
values are:
a2a1 -- a2b0 a1e3 -- a2e4 a1ef -- a2f0 a2fd -- a1fe a4f4 -- a4fe a5f7 -- a5fe a6b9 -- a6c0 a6d9 -- a6fe a7c2 -- a7d0 a7f2 -- a7fe a8bb -- a8c4 a8ea -- a9a3 a9f0 -- affe a7fa -- d7fe f8a1 -- fedf |
| IBM-sbdCN | Scattered in GB. It occupies positions 0xfee0 to 0xfefe. |
GBK stands for Guo (national) Biao (Standard) Kuo (Extension). GB18030 expands the national "Industry GB" definition to contain all 20, 902 Han Characters defined in Unicode and additional DBCS symbols defined in Big-5 code (Traditional Chinese PC defacto standard). GB18030 defines all DBCS characters and symbols in use in the People's Republic of China and in Taiwan.
| Locale | Code Set | Description |
|---|---|---|
| Zh_CN | GB18030 | Simplified Chinese, GB18030 Locale |
| Code Range | Words | Marks |
|---|---|---|
| A1A1-A9FE | 846 | GB2312, GB12345 (GBK/1) |
| A840-A9A0 | 192 | Big5, Symbols (GBK/5) |
| B0A1-F7FE | 6768 | GB2312 (GBK/2) |
| 8140-A0FE | 6080 | GB13000 (GBK/3) |
| AA40-FEA0 | 8160 | GB13000 (GBK/4) |
| AAA1-AFFE | 564 | User defined 1 |
| F8A1-FEFE | 658 | User defined 2 |
| A140-A7A0 | 672 | User defined 3 |
The EUC for the Traditional Chinese language is an encoding consisting of characters that contain 1, 2 and 4 bytes. The EUC encoding is based on ISO2022, the Chinese National Standard (CNS) as defined by Taiwan, and multibyte character definitions unique to the manufacturer.
The current CNS defines 13,501 Chinese characters and 684 symbols. The IBM-eucTW is based upon a concept of 15 planes, each containing up to 8836 (94x94) characters. The encoding values of these characters range from 0xa1a1 to 0xfefe. Characters have presently been defined for only 4 of the planes, with the other planes being reserved for future expansion.
The 15 planes are mapped into the CS1 and CS2 of EUC, with the CS2 of EUC consisting of 14 planes. Specifically, the IBM-eucTW consists of the following character sets:
| ISO646-IRV | 7-bit ASCII character set, Graphic Left. |
| CNS11643.1986-1 | Plane 1, containing 6085 characters (5401+684). This plane uses positions 0ax1a1-0xc2c1 and 0xc4a1-0xfdcb. |
| CNS11643.1986-2 | Plane 2, containing 7650 characters. This plane occupies positions 0x8ea2a1a1-0x8ea2f2c4. |
| CNS11643.1992-3 | Plane 4, containing 7298 characters. This plane occupies positions 0x8ea4a1a1-0x8ea4eedc. |
| IBM-udcTW | Plane 12, containing 6204 characters. This plane is reserved for the User Defined Characters (udc) areas. It occupies the positions 0x8eaca1a1-0x8ea2f2c4. |
| IBM-sbdTW | Plane 13, containing 325 characters. This plane is reserved for symbols unique to the manufacturer. It occupies positions 0xeada1a1-0x8eada4cb. |
Planes 3-11 are expected to occupy positions 0x8ea3xxxx to 0x8eabxxxx. Planes 14-15 are expected to occupy positions 0x8eaexxxx to 0x8eafxxxx.
The Traditional Chinese big5 locale, Zh_TW, code set is the most commonly used code set in the PC field that is used to support countries using Traditional Chinese.
Big5 code set defines 13056 characters and 1004 symbols. It includes 684 symbols in CNS11643.192, as well as 325 symbols unique to IBM.
| Locale | Code Set | Description |
|---|---|---|
| Zh_TW | Big5 (IBM-950) | Traditional Chinese, Big5 Locale |
| Plan | Code Range | Description |
|---|---|---|
| 1 | A140H - A3E0H | Symbol and Chinese Control Code |
| 1 | A440H - C67EH | Commonly Used Characters |
| 2 | C940H - F9D5H | Less Commonly Used Characters |
| UDF | FA40H - FEFE | User-Defined Characters |
|
|
8E40H - A0FEH | User-Defined Characters |
|
|
8140H - 8DFEH | User-Defined Characters |
|
|
8181H - 8C82H | User-Defined Characters |
|
|
F9D6H - F9F1H | User-Defined Characters |
| Code Set | Words | Code Range | Marks |
|---|---|---|---|
| Commonly Used Area | 5841 | A140-C67E |
|
| Less Commonly Used Area | 7652 | C940-F9D5 |
|
| ET Unique Area (1) | 308 | C6A1-C878 |
|
| ET Unique Area (2) | 7 | C8CD-C8D3 |
|
| IBM Unique Area | 251 | F286-F9A0 | Low-Byte Range 81-A0 |
| User-Defined Area (1) | 785 | FA40-FEFE |
|
| User-Defined Area (2) | 2983 | 8E40-A0FE |
|
| User-Defined Area (3) | 2041 | 8140-8DFE |
|
| User-Defined Area (4) | 354 | 8181-8C82 | Low-Byte Range 81-AQ |
| User-Defined Area (5) | 41 | F9D6-F9FE |
|
The EUC for the Korean language is an encoding consisting of single-byte and multibyte characters. The encoding is based on ISO2022, Korean Standard Code set, and EUC definitions.
The Korean EUC code set consists of the following main character groups:
The Hangul code set includes Hangul and Hanja (Chinese) characters. One Hangul character can comprise several consonants and vowels. However, most Hangul words can be expressed in Hanja. Each Hanja character has its own meaning and is more specific than Hangul.
The IBM-eucKR consists of the following character sets:
| ISO646-IRV | 7-bit ASCII character set, Graphic Left |
| KSC5601.1987-0 | Korean Graphic Character Set, Graphic Right |
IBM PC code sets are the code sets originally supported on the IBM PC systems and AIX. The IBM PC code sets assign graphic characters to the Control One (C1) control area. Applications that depend on these control characters cannot support these code sets.
The ASCII characters are encoded with the most significant bit (MSB) zero in positions 0x20-0x7e. The extended Latin 1, combined with the IBM PC unique character sets, make up the extended set of characters which are encoded in positions 0x80-0xfe. The following table shows the location of the control, ASCII, and extended characters for the IBM-850 code set.
| Character Encoding | Code Point | Description | Count |
|---|---|---|---|
| 000xxxxx | 00-1F | Controls | 32 |
| 00100000 | 20 | Space | 1 |
| 0xxxxxxx | 21-7E | 7-bit | 94 |
| 01111111 | 7F | Delete | 1 |
| 1xxxxxxx | 80-FE | 8-bit | 17 |
| 11111111 | FF | All ones | 1 |
The IBM PC unique character set includes the following:
| IBM PC Unique Character Set | |
|---|---|
| Symbol | Return Code |
| Florin sign | 0x9f |
| Quarter-hashed | 0xb0 |
| Half-hashed | 0xb1 |
| Full-hashed | 0xb2 |
| Vertical bar | 0xb3 |
| Right-side middle | 0xb4 |
| Double right-side middle | 0xb9 |
| Double vertical bar | 0xba |
| Double upper right-corner box | 0xbb |
| Double lower right-corner box | 0xbc |
| Upper right-corner box | 0xbf |
| Lower left-corner box | 0xc0 |
| Bottom-side middle | 0xc1 |
| Top-side middle | 0xc2 |
| Left-side middle | 0xc3 |
| Center-box bar | 0xc4 |
| Intersection | 0xc5 |
| Double lower left-corner box | 0xc8 |
| Double upper left-corner box | 0xc9 |
| Double bottom-side middle | 0xca |
| Double top-side middle | 0xcb |
| Double left-side middle | 0xcc |
| Double center-box bar | 0xcd |
| Double intersection | 0xce |
| Small i dotless | 0xd5 |
| Lower right-corner box | 0xd9 |
| Upper left-corner box | 0xda |
| Bright character cell | 0xdb |
| Bright character cell - lower half | 0xde |
| Bright character cell - upper half | 0xdf |
| Overbar | 0xee |
| Middle dot, Product dot | 0xfa |
| Vertical solid rectangle | 0xfe |
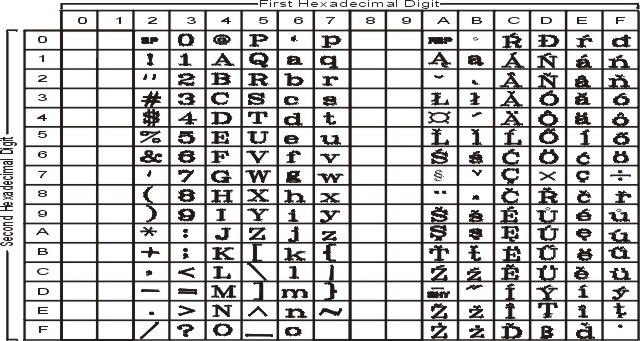
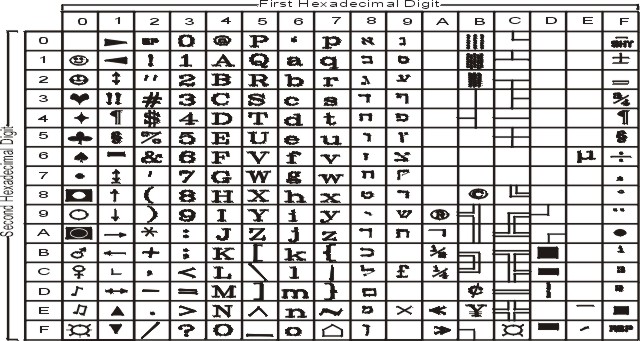
The following figure summarizes the available symbols and shows the layout of Code Set IBM-856. For a textual representation of this code set, see IBM-856.
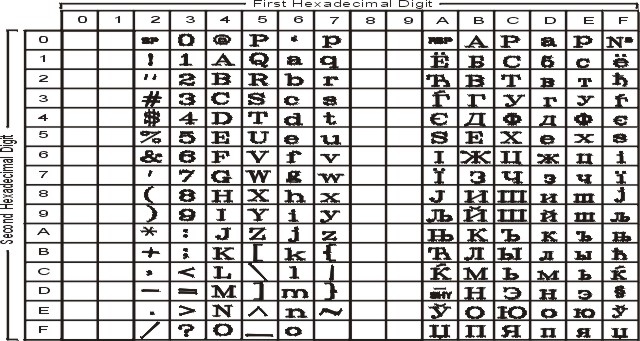
The following figure summarizes the available symbols and shows the layout of Code Set IBM-921. For a textual representation of this code set, see IBM-921.
The following figure summarizes the available symbols and shows the layout of Code Set IBM-922. For a textual representation of this code set, see IBM-922.
Each of the Japanese IBM PC code sets are an encoding consisting of single-byte and multibyte coded characters. The encoding is based on the IBM PC code set and places the JIS characters in shifted positions. This is referred to as Shift-JIS or SJIS.
IBM-943 is a newer code set for the Japanese locale than IBM-932. IBM-943 is a compatible code set for the Japanese Microsoft Windows environment. This code set is known as 1983 ordered shift-JIS. The differences between IBM-932 and IBM-943 are as follows:
The IBM-932 code set consists of the following character sets:
| JISCII | JISX0201 Graphic Left character set |
| JISX0201.1976 | Katakana/Hiragana Graphic Right character set |
| JISX0208.1983 | Kanji level 1 and 2 character sets |
| IBM-udcJP | IBM user-definable characters |
The IBM-943 code set consists of the following character sets:
| JISCII | JISX0201 Graphic Left character set |
| JISX0201.1976 | Katakana/Hiragana Graphic Right character set |
| JISX0208.1990 | Kanji level 1 and 2 character sets |
| IBM-udcJP | IBM user-definable characters and NEC's IBM selected characters and NEC selected characters |
The first byte of each character is used to determine the number of bytes for a given character. The values 0x20-0x7e and 0xa1-oxdf are used to encode JISX0201 characters, with exceptions. The positions 0x81-0x9f and 0xe0-0xfc are reserved for use as the first byte of a multibyte character. The JISX0208 characters are mapped to the multibyte values starting at 0x8140. The second byte of a multibyte character can have any value. The Shift-JIS table shows where these characters are located on the code set.
| Character Encoding | Code Point | Description | Count |
|---|---|---|---|
| 000xxxxx | 00-1f | Controls | 32 |
| 00100000 | 20 | Space | 1 |
| 0xxxxxxx | 21-7E | 7-bit ASCII | 94 |
| 01111111 | 7F | Delete | 1 |
| 10000000 | 80 | Undefined | 1 |
| 100xxxxx 01xxxxxx | [81-9F] [40-7E] | Double byte | 1953 |
| 100xxxxx 1xxxxxxx | [81-9F] [80-FC] | Double byte | 3975 |
| 10100000 | A0 | Undefined | 1 |
| 1xxxxxxx | A1-DF | 7-bit single byte | 63 |
| 111xxxxx 01xxxxxx | [E0-FC] [40-7E] | Double byte | 1827 |
| 111xxxxx 1xxxxxxx | [E0-FC] [80-FC] | Double byte | 3625 |
| 11111101 | FD | Undefined | 1 |
| 11111110 | FE | Undefined | 1 |
| 11111111 | FF | Undefined | 1 |
The following table shows the DBCS portion of IBM-943.
| Code Point | Description |
|---|---|
| [81-84] [40-7E] and [81-84] [80-F0] | JIS X 0208 (Non-Kanji) |
| [87] [40-7E] and [87] [80-F0] | NEC selected characters |
| [89-98] [40-7E] and [88] [9F-F0], [89-97] [80-F0], [98] [80-9F] | JIS X0208 (Level-1 Kanji) |
| [99-9F] [40-7E] and [98] [9F-F0], [99-9F] [80-F0] | JIS X0208 (Level-2 Kanji) |
| [E0-EA] [40-7E] and [E0-EA] [80-F0] | JIS X0208 (Level-2 Kanji) |
| [ED-EE] [40-7E] and [ED-EE] [80-F0] | NEC IBM selected characters |
| [F0-F9] [40-7E] and [F0-F9] [80-F0] | User-defined characters |
| [FA] [40-5C] | IBM selected characters (non-Kanji) |
| [FA] [5C-7E], [FB-FC] [40-7E] and [FA-FC] [80-F0] | IBM selected characters (Kanji) |
The following table shows the DBCS portion of IBM-932.
| Code Point | Description |
| [81-98] [40-7E] and [81-97] [80-FC], [98] [80-9F] | JIS X 0208 (Level-1 Kanji) |
| [99-9F] [40-7E] and [98] [9F-FC], [99-9F] [80-FC] | JIS X 0208 (Level-2 Kanji) |
| [E0-EF] [40-7E] and [E0-EF] [80-FC] | JIS X 0208 (Level-2 Kanji) |
| [F0-F9] [40-7E] and [F0-F9] [80-FC] | User-defined characters |
| [FA-FC] [40-7E] and [FA-FC] [80-FC] | IBM selected characters |
The following figure summarizes the available symbols and shows the layout of Code Set IBM-1046. For a textual representation of this code set, see IBM-1046.
The following figure summarizes the available symbols and shows the layout of Code Set IBM-1124. For a textual representation of this code set, see IBM-1124.
The following figure summarizes the available symbols and shows the layout of Code Set IBM-1129. For a textual representation of this code set, see IBM-1129.
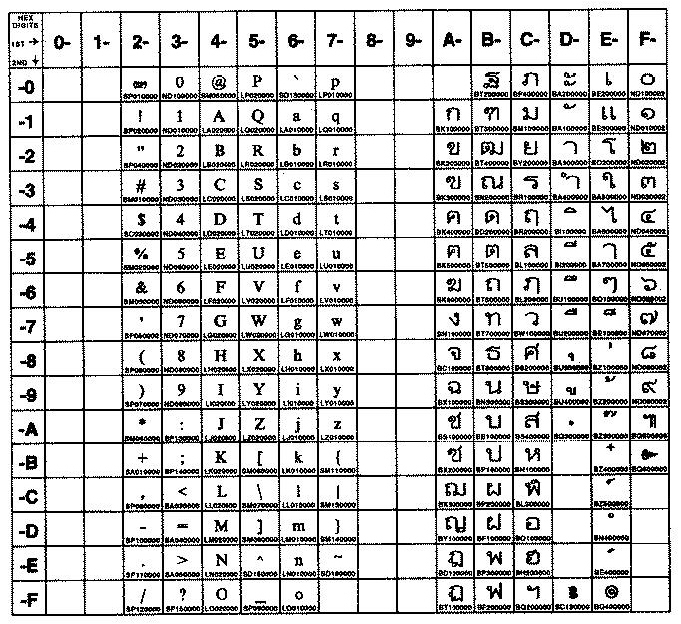
The following figure summarizes the available symbols and shows the layout of Code Set TIS-620. For a textual representation of this code set, see TIS-620.
AIX provides a set of codesets that address the needs of a particular language or a language group. None of the codesets represented in the ISO8859 family of codesets, the PC codesets, nor the Extended UNIX Code (EUC) codesets allow the mixing of characters from different scripts. With ISO8859-1, you can mix and represent the Latin 1 characters (languages principally spoken in the U.S., Canada, Western Europe, and Latin America). ISO8859-2 covers Eastern European languages; ISO8859-5 covers Cyrillic, ISO8859-6 covers Arabic, ISO8859-7 covers Greek, ISO8859-8 covers Hebrew, ISO8859-9 covers Turkish, IBM-eucJP covers Japanese, IBM-eucKR covers Korean, IBM-eucTW covers Traditional Chinese. The point is that none of the above codesets covers all of the languages.
The International Organization for Standardization (ISO) addressed the limited language coverage by code sets by adopting Unicode as the encoding for the 2-octet form of the ISO10646 Universal Multiple-Octet Coded Character Set (UCS-2). The 32-bit form of ISO10646 is known as UCS-4 for 4-octet form. AIX uses the 16-bit form of ISO10646 and uses the standard label UCS-2 to describe this encoding.
Although UCS-2 is ideal for an internal process code, it is not suitable for encoding plain text on traditional byte-oriented systems, such as AIX. Therefore, the external file code is The Open Group's File System Safe UCS Transformation Format (FSS-UTF). This transformation format encoding is also known as UTF-8, and UTF-8 is the label that is used for this encoding on AIX.
Universal Coded Character Set (UCS) is the name of the ISO10646 standard that defines a single code for the representation, interchange, processing, storage, entry, and presentation of the written form of all the major languages of the world.
ISO10646 defines canonical character codes with a length of 32 bits, which provides code numbers for over 4 billion characters. When used in canonical form to represent text, the coding is referred to as UCS-4 for Universal Coded Character Set 4-byte form.
The code values from 0x0000 through 0xFFFF of ISO 10646 can be represented by a uniform character encoding of 16 bits. When used in this form to represent text, these codes are referred to as UCS-2, for Universal Character Set 2-octet form. This range is also called the Basic Multilingual Plane (BMP) of ISO10646. The standard is arranged so that the most useful characters, covering all major existing standards worldwide, are assigned within this range.
The character code values of UCS-2 are identical to those of the Unicode character encoding standard published by the Unicode Consortium. UCS-2 defines codes for characters used in all major written languages. In addition to a set of scientific, mathematic, and publishing symbols, UCS-2 covers the following scripts:
The ability of AIX to display characters in the scripts mentioned above is limited to the availability of fonts. AIX provides bitmap fonts for most of the major languages of the world, as well as a Unicode-based scalable TrueType font. Use of this font requires the TrueType font rasterizer for AIX, which is a separately installable feature.
UCS-2 encodes a number of combining characters, also known as non-spacing marks for floating diacritics. These characters are necessary in several scripts including Indic, Thai, Arabic, and Hebrew. The combining characters are used for generating characters in Latin, Cyrillic, and Greek scripts. However, the presence of combining characters creates the possibility for an alternative coding for the same text. Although the coding is unambiguous and data integrity is preserved, the processing of text that contains combining characters is more complex. To provide conformance for applications that choose not to deal with the combining characters, ISO10646 defines the following implementation levels:
The Unicode standard is used to define standard character encodings for most of the commonly used languages in the world. The 2-byte form of this standard is commonly referred to as UCS-2. However, UCS-2 is only capable of representing a maximum of 65,536 characters as a 2-byte quantity. The 4-byte form of Unicode is referred to as UCS-4 or UTF-32, and is capable of defining the complete extensions of Unicode, with a maximum of over 1,000,000 unique characters definable.
The Open Group has developed a transformation format for UCS designed for use in existing file systems. The intent is that UCS will be the process code for the transformation format, which is usable as a file code.
UTF-8 has the following properties:
The UTF-8 encodes UCS values in the 0 through 0x7FFFFFFF range using multibyte characters with lengths of 1, 2, 3, 4, 5, and 6 bytes. Single-byte characters are reserved for the ASCII characters in the 0 through 0x7f range. These characters all have the high order bit set to 0. For all character encodings of more than one byte, the initial byte determines the number of bytes used, and the high-order bit in each byte is set. Every byte that does not start with the bit combination of 10xxxxxx, where x represents a bit that may be 0 or 1, is the start of a UCS character sequence. The following table provides UTF-8 multibyte codes:
| Bytes | Bits | Hex Minimum | Hex Maximum | Byte Sequence in Binary |
|---|---|---|---|---|
| 1 | 7 | 00000000 | 0000007F | 0xxxxxxx |
| 2 | 11 | 00000080 | 000007FF | 110xxxxx 10xxxxxx |
| 3 | 16 | 00000800 | 0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 21 | 00010000 | 001FFFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 5 | 26 | 00200000 | 03FFFFFF | 111110xx 10xxxxxx 10xxxxxx 10xxxxx 10xxxxxx |
| 6 | 31 | 04000000 | 7FFFFFFF | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
The UCS value is just the concatenation of the x bits in the multibyte encoding. When there are multiple ways to encode a value (for example, UCS 0), only the shortest encoding is permitted.
The following subset of UTF-8 is used to encode UCS-2:
| Bytes | Bits | Hex Minimum | Hex Maximum | Byte Sequence in Binary |
|---|---|---|---|---|
| 1 | 7 | 00000000 | 0000007F | 0xxxxxxx |
| 2 | 11 | 00000080 | 000007FF | 110xxxxx 10xxxxxx |
| 3 | 16 | 00000800 | 0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
This subset of UTF-8 requires a maximum of three (3) bytes.
UTF-16 is the UCS Transformation Format for 16 planes of Group 00. UTF-16 is the ISO/IEC encoding that is equivalent to the Unicode Standard with the use of surrogates. In UTF-16, each UCS-2 code value represents itself. Non-BMP code values of ISO/EIC 10646 in planes 1..16 are represented using pairs of special codes. UTF-16 defines the transformation between the UCS-4 code positions in planes 1 to 16 of Group 00 and the pairs of special codes, and is identical to the transformation defined in the Unicode Standard.
Low Function Terminal (LFT) Subsystem Overview in AIX 5L Version 5.2 Kernel Extensions and Device Support Programming Concepts.
Keyboard Overview