This section discusses performance related topics for the processor Scheduler.
A thread can be thought of as a low-overhead process. It is a dispatchable entity that requires fewer resources to create than a process. The fundamental dispatchable entity of the AIX Version 4 scheduler is the thread.
Processes are composed of one or more threads. In fact, workloads migrated directly from earlier releases of the operating system continue to create and manage processes. Each new process is created with a single thread that has its parent process priority and contends for the processor with the threads of other processes. The process owns the resources used in execution; the thread owns only its current state.
When new or modified applications take advantage of the operating system's thread support to create additional threads, those threads are created within the context of the process. They share the process's private segment and other resources.
A user thread within a process has a specified contention scope. If the contention scope is global, the thread contends for processor time with all other threads in the system. The thread that is created when a process is created has global contention scope. If the contention scope is local, the thread contends with the other threads within the process to be the recipient of the process's share of processor time.
The algorithm for determining which thread should be run next is called a scheduling policy.
A process is an activity within the system that is started by a command, a shell program, or another process.
Process properties are as follows:
These properties are defined in /usr/include/sys/proc.h.
Thread properties are as follows:
These thread properties are defined in /usr/include/sys/thread.h.
Each process is made up of one or more threads. A thread is a single sequential flow of control. Multiple threads of control allow an application to overlap operations, such as reading from a terminal and writing to a file.
Multiple threads of control also allow an application to service requests from multiple users at the same time. Threads provide these capabilities without the added overhead of multiple processes such as those created through the fork() system call.
AIX 4.3.1 introduced a fast fork routine called f_fork(). This routine is very useful for multithreaded applications that will call the exec() subroutine immediately after they would have called the fork() subroutine. The fork() subroutine is slower because it has to call fork handlers to acquire all the library locks before actually forking and letting the child run all child handlers to initialize all the locks. The f_fork() subroutine bypasses these handlers and calls the kfork() system call directly. Web servers are a good example of an application that can use the f_fork() subroutine.
The priority management tools manipulate process priority. In AIX Version 4, process priority is simply a precursor to thread priority. When the fork() subroutine is called, a process and a thread to run in it are created. The thread has the priority that would have been attributed to the process.
The kernel maintains a priority value (sometimes termed the scheduling priority) for each thread. The priority value is a positive integer and varies inversely with the importance of the associated thread. That is, a smaller priority value indicates a more important thread. When the scheduler is looking for a thread to dispatch, it chooses the dispatchable thread with the smallest priority value.
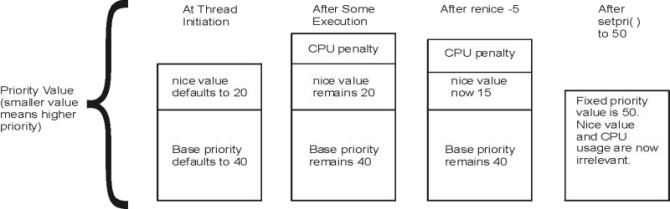
A thread can be fixed-priority or nonfixed priority. The priority value of a fixed-priority thread is constant, while the priority value of a nonfixed-priority thread varies based on the minimum priority level for user threads (a constant 40), the thread's nice value (20 by default, optionally set by the nice or renice command), and its processor-usage penalty.
The priority of a thread can be fixed at a certain value, which can have a priority value less than 40, if their priority is set (fixed) through the setpri() subroutine. These threads are immune to the scheduler recalculation algorithms. If their priority values are fixed to be less than 40, these threads will run and complete before any user threads can run. For example, a thread with a fixed value of 10 will run before a thread with a fixed value of 15.
Users can apply the nice command to make a thread's nonfixed priority less favorable. The system manager can apply a negative nice value to a thread, thus giving it a better priority.
The following illustration shows some of the ways in which the priority value can change.
The nice value of a thread is set when the thread is created and is constant over the life of the thread, unless explicitly changed by the user through the renice command or the setpri(), setpriority(), thread_setsched(), or nice() system calls.
The processor penalty is an integer that is calculated from the recent processor usage of a thread. The recent processor usage increases by approximately 1 each time the thread is in control of the processor at the end of a 10 ms clock tick, up to a maximum value of 120. The actual priority penalty per tick increases with the nice value. Once per second, the recent processor usage values for all threads are recalculated.
The result is the following:
You can use the ps command to display the priority value, nice value, and short-term processor-usage values for a process.
See Controlling Contention for the processor for a more detailed discussion on using the nice and renice commands.
See Tuning the Thread-Priority-Value Calculation, for the details of the calculation of the processor penalty and the decay of the recent processor usage values.
The priority mechanism is also used by AIX Workload Manager to enforce processor resource management. Because threads classified under the Workload Manager have their priorities managed by the Workload Manager, they might have different priority behavior over threads not classified under the Workload Manager.
The following are the possible values for thread scheduling policy:
The scheduling policies are set with the thread_setsched() system call and are only effective for the calling thread. However, a thread can be set to the SCHED_RR scheduling policy by issuing a setpri() call specifying the process ID; the caller of setpri() and the target of setpri() do not have to match.
Only processes that have root authority can issue the setpri() system call. Only threads that have root authority can change the scheduling policy to any of the SCHED_FIFO options or SCHED_RR. If the scheduling policy is SCHED_OTHER, the priority parameter is ignored by the thread_setsched() subroutine.
Threads are primarily of interest for applications that currently consist of several asynchronous processes. These applications might impose a lighter load on the system if converted to a multithreaded structure.
The scheduler maintains a run queue of all of the threads that are ready to be dispatched. The following illustration depicts the run queue symbolically.
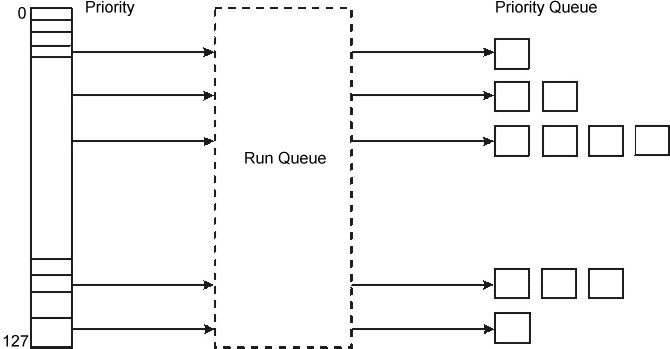
All the dispatchable threads of a given priority occupy positions in the run queue.
The fundamental dispatchable entity of the scheduler is the thread. AIX 5.1 maintains 256 run queues (128 in AIX 4.3 and prior releases). In AIX 5.1, run queues relate directly to the range of possible values (0 through 255) for the priority field for each thread.. This method makes it easier for the scheduler to determine which thread is most favored to run. Without having to search a single large run queue, the scheduler consults a mask where a bit is on to indicate the presence of a ready-to-run thread in the corresponding run queue.
The priority value of a thread changes rapidly and frequently. The constant movement is due to the way that the scheduler recalculates priorities. This is not true, however, for fixed-priority threads.
Starting with AIX 4.3.3, each processor has its own run queue. The run queue values reported in the performance tools will be the sum of all the threads in each run queue. Having a per-processor run queue saves overhead on dispatching locks and improves overall processor affinity. Threads will tend to stay on the same processor more often. If a thread becomes runnable because of an event on another processor than the one in which the newly runnable thread had been running on, then this thread would only get dispatched immediately if there was an idle processor. No preemption occurs until the processor's state can be examined (such as an interrupt on this thread's processor).
On multiprocessor systems with multiple run queues, transient priority inversions can occur. It is possible at any point in time that one run queue could have several threads having more favorable priority than another run queue. AIX has mechanisms for priority balancing over time, but if strict priority is required (for example, for real-time applications) an environment variable called RT_GRQ exists, that, if set to ON, will cause this thread to be on a global run queue. In that case, the global run queue is searched to see which thread has the best priority. This can improve performance for threads that are interrupt driven. Threads that are running at fixed priority are placed on the global run queue if schedtune -F is set to 1.
The average number of threads in the run queue can be seen in the first column of the vmstat command output. If you divide this number by the number of processors, the result is the average number of threads that can be run on each processor. If this value is greater than one, these threads must wait their turn for the processor (the greater the number, the more likely it is that performance delays are noticed).
When a thread is moved to the end of the run queue (for example, when the thread has control at the end of a time slice), it is moved to a position after the last thread in the queue that has the same priority value.
The processor time slice is the amount of time a SCHED_RR thread can absorb before the scheduler switches to another thread at the same priority. You can use the -t option of the schedtune command to increase the number of clock ticks in the time slice by 10 millisecond increments (see Modifying the Scheduler Time Slice with the schedtune Command).
A user process undergoes a mode switch when it needs access to system resources. This is implemented through the system call interface or by interrupts such as page faults. There are two modes:
Processor time spent in user mode (application and shared libraries) is reflected as user time in the output of commands such as the vmstat, iostat, and sar commands. Processor time spent in kernel mode is reflected as system time in the output of these commands.
Programs that execute in the user protection domain are user processes. Code that executes in this protection domain executes in user execution mode, and has the following access:
Programs executing in the user protection domain do not have access to the kernel or kernel data segments, except indirectly through the use of system calls. A program in this protection domain can only affect its own execution environment and executes in the process or unprivileged state.
Programs that execute in the kernel protection domain include interrupt handlers, kernel processes, the base kernel, and kernel extensions (device driver, system calls and file systems). This protection domain implies that code executes in kernel execution mode, and has the following access:
Kernel services must be used to access user data within the process address space.
Programs executing in this protection domain can affect the execution environments of all programs, because they have the following characteristics:
The use of a system call by a user-mode process allows a kernel function to be called from user mode. Access to functions that directly or indirectly invoke system calls is typically provided by programming libraries, which provide access to operating system functions.
Mode switches should be differentiated from the context switches seen in the output of the vmstat (cs column) and sar (cswch/s) commands. A context switch occurs when the currently running thread is different from the previously running thread on that processor.
The scheduler performs a context switch when any of the following occurs:
Context switch time, system calls, device interrupts, NFS I/O, and any other activity in the kernel is considered as system time.