The NIS+ namespace is the arrangement of information stored by NIS+. The namespace can be arranged in a variety of ways to suit the needs of an organization. For example, if an organization had three divisions, its NIS+ namespace would likely be divided into three parts, one for each division. Each part would store information about the users, workstations, and network services in its division, but the parts could easily communicate with each other. Such an arrangement would make information easier for the users to access and for the administrators to maintain.
Although the arrangement of an NIS+ namespace can vary from site to site, all sites use the same structural components: directories, tables, and groups. These components are called NIS+ objects. NIS+ objects can be arranged into a hierarchy.
Although an NIS+ namespace resembles a traditional UNIX file system, it has five important differences:
Directory objects are the skeleton of the namespace. When arranged into a tree-like structure, they divide the namespace into separate parts. A directory hierarchy is similar to an inverted tree, with the root of the tree at the top and the branches toward the bottom. The topmost directory in a namespace is the root directory. If a namespace is flat, it has only one directory, but that directory is nevertheless the root directory. The directory objects beneath the root directory are simply called directories.
A namespace can have several levels of directories. When identifying the relation of one directory to another, the directory beneath is called the child directory and the directory above is called the parent directory.
Whereas traditional UNIX directories are designed to hold traditional UNIX files, NIS+ directories are designed to hold NIS+ objects: other directories, tables and groups. Any NIS+ directory that stores NIS+ groups is named groups_dir. Any directory that stores NIS+ system tables is named org_dir.
You can arrange directories, tables, and groups into any structure that you like. However, NIS+ directories, tables, and groups in a namespace are normally arranged into configurations called domains. Domains are designed to support separate portions of the namespace. For instance, one domain may support the Sales Division of a company, while another may support the Manufacturing Division.
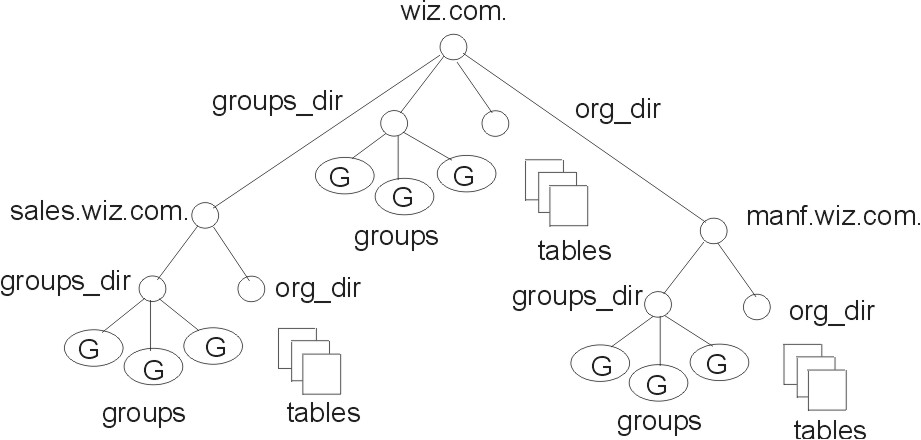
An NIS+ domain consists of a directory object, its org_dir directory, its groups_dir directory, and a set of NIS+ tables. NIS+ domains are not tangible components of the namespace. They are simply a convenient way to refer to sections of the namespace that are used to support real-world organizations. For example, assume that the Wizard Corporation has a Sales division and an Manufacturing division. To support those divisions, its NIS+ namespace would most likely be arranged into three major directory groups, with a structure such as the one shown in the following figure.
Figure 4-1. Example Structure of an NIS+ Namespace. An example structure of a hierarchical NIS+ namespace. wiz.com. contains groups, tables, and directories as well as the subdomains of sales.wiz.com. and manf.wiz.com., each of which contains its own directories, tables, and groups.
|
Instead of referring to such a structure as three directories, six subdirectories, and several additional objects, referring to it as three domains is more convenient.
Setting Up the Root Domain and Setting Up a Nonroot Domain describe how to configure domains.
Every NIS+ domain is supported by a set of NIS+ servers. The servers store the domain's directories, groups, and tables, and answer requests for access from users, administrators, and applications. Each domain is supported by only one set of servers. However, a single set of servers can support more than one domain.
Remember that a domain is not an object but only refers to a collection of objects. Therefore, a server that supports a domain is not actually associated with the domain, but with the domain's main directory. This connection between the server and the directory object is established during the process of setting up a domain. Although instructions are provided in Chapter 5, NIS+ Installation and Configuration, one thing is important to mention now: when that connection is established, the directory object stores the name and IP address of its server. This information is used by clients to send requests for service, as described later in this section.
Any workstation can be an NIS+ server. The software for both NIS+ servers and clients is bundled together into the release. Therefore, any workstation with the BOS installed can become a server or a client, or both. What distinguishes a client from a server is the role it is playing. If a workstation is providing NIS+ service, it is acting as an NIS+ server. If it is requesting NIS+ service, it is acting as an NIS+ client.
Because of the need to service many client requests, a workstation that will act as an NIS+ server might be configured with more computing power and more memory than the average client. And, because it needs to store NIS+ data, it might also have a larger disk. However, other than hardware to improve its performance, a server is not inherently different from an NIS+ client.
Two types of servers support an NIS+ domain: a master and its replicas. The master server of the root domain is called the root master server. A namespace has only one root master server. The master servers of other domains are simply called master servers. Likewise, there are root replica servers and regular replica servers.
Both master and replica servers store NIS+ tables and answer client requests. The master, however, stores the master copy of a domain's tables. The replicas store only duplicates. The administrator loads information into the tables in the master server, and the master server propagates it to the replica servers.
This arrangement has two benefits. First, it avoids conflicts between tables because only one set of master tables exists; the tables stored by the replicas are only copies of the masters. Second, it makes the NIS+ service much more available. If either the master or a replica is down, another server can act as a backup and handle the requests for service.
Note: If the root master server is unavailable and the NIS+ domain is being served solely by a replica, you can obtain information from the NIS+ tables, but changes to the original tables can be made only when the master server is available.
An NIS+ master server implements updates to its objects immediately; however, it tries to "batch" several updates together before it propagates them to its replicas. When a master server receives an update to an object, whether a directory, group, link, or table, it waits about two minutes for any other updates that may arrive. Once it is finished waiting, it stores the updates in two locations: on disk and in a transaction log (it has already stored the updates in memory).
The transaction log is used by a master server to store changes to the namespace until they can be propagated to replicas. A transaction log, as shown in the following figure, has two primary components: updates and time stamps.
Figure 4-2. Structure of a Transaction Log. This illustration shows a transaction log represented by a linear series of blocks, the first eight of which are labeled Update. Timestamps are inserted. The last timestamp is the server's and all other timestamps are replicas. Replicas must update from the server's timestamp.
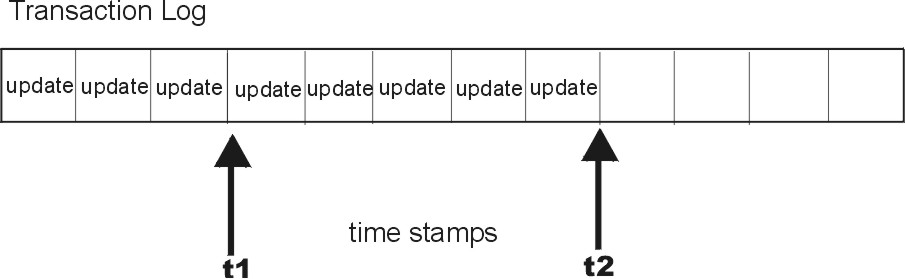 |
An update is an actual copy of a changed object. For instance, if a directory has been changed, the update is a complete copy of the directory object. If a table entry has been changed, the update is a copy of the actual table entry. The time stamp indicates the time at which an update was made by the master server.
After recording the change in the transaction log, the master sends a message to its replicas, telling them that it has updates to send them. Each replica replies with the time stamp of the last update it received from the master. The master then sends each replica the updates it has recorded in the log since the replica's time stamp.
When the master server updates all its replicas, it clears the transaction log. In some cases, such as when a new replica is added to a domain, the master receives a time stamp from a replica that is before its earliest time stamp still recorded in the transaction log. In this situation, the master server performs a full resynchronization, or resync. A resync downloads all the objects and information stored in the master down to the replica. During a resync, both the master and replica are busy. The replica cannot answer requests for information; the master can answer read requests but cannot accept update requests. Both respond to requests with a Server Busy - Try Again or similar message.
Attention: The clocks of the server and clients must be synchronized to each other. If this is not done, credential clarification fails.