The policies described in this section help you set a strategy for logical volume use that is oriented toward a combination of availability, performance, and cost that is appropriate for your site.
Availability is the ability to recover data that is lost because of disk, adapter, or other hardware problems. The recovery is made from copies of the data that are made and maintained on separate disks and adapters during normal system operation.
Performance is the average speed at which data is accessed. Policies such as write-verify and mirroring enhance availability but add to the system processing load, and thus degrade performance. Mirroring doubles or triples the size of the logical volume. In general, increasing availability degrades performance. Disk striping can increase performance. Beginning with AIX 4.3.3, disk striping is allowed with mirroring.
By controlling the allocation of data on the disk and between disks, you can tune the storage system for the highest possible performance. See Monitoring and Tuning Memory Use, and Monitoring and Turning Disk I/O, in AIX 5L Version 5.1 Performance Management Guide for detailed information on how to maximize storage-system performance.
The sections that follow should help you evaluate the tradeoffs among performance, availability, and cost. Remember that increased availability often decreases performance, and vice versa. Mirroring may increase performance, however, if the LVM chooses the copy on the least busy disk for Reads.
Note: Mirroring does not protect against the loss of individual files that are accidentally deleted or lost because of software problems. These files can only be restored from conventional tape or diskette backups.
It is important that you understand the material contained in the Logical Volume Storage Overview.
Determine whether the data that is stored in the logical volume is valuable enough to warrant the processing and disk-space costs of mirroring.
Performance and mirroring are not always opposed. If the different instances (copies) of the logical partitions are on different physical volumes, preferably attached to different adapters, the LVM can improve Read performance by reading the copy on the least busy disk. Write performance, unless disks are attached to different adapters, always cost the same because you must update all copies. It is only necessary to read one copy for a Read operation.
If you have a large sequential-access file system that is performance-sensitive, you may want to consider disk striping.
Normally, whenever data on a logical partition is updated, all the physical partitions containing that logical partition are automatically updated. However, physical partitions can become stale (no longer containing the most current data) because of system malfunctions or because the physical volume was unavailable at the time of an update. The LVM can refresh stale partitions to a consistent state by copying the current data from an up-to-date physical partition to the stale partition. This process is called mirror synchronization. The refresh can take place when the system is restarted, when the physical volume comes back online, or when you issue the syncvg command.
While mirroring improves storage system availability, it is not intended as a substitute for conventional tape backup arrangements.
Beginning with AIX 4.3.3, the startup logical volume can be mirrored.
Any change that affects the physical partition makeup of a boot logical volume requires that you run bosboot after that change. This means that actions such as changing the mirroring of a boot logical volume require a bosboot.
Avoid dumping to a mirrored logical volume because it results in an inconsistent dump. Because the default dump device is the primary paging logical volume, create a separate dump logical volume if you mirror your paging logical volumes. If you mirror your root volume group, also create a separate dump logical volume.
For data that has only one physical copy, the logical volume device driver (LVDD) translates a logical Read or Write request address into a physical address and calls the appropriate physical device driver to service the request. This single-copy or nonmirrored policy handles bad block relocation for Write requests and returns all Read errors to the calling process.
If you use mirrored logical volumes, four different scheduling policies for writing to disk can be set for a logical volume with multiple copies. They are sequential, parallel, parallel write with sequential read, and parallel write with round robin read.
When Mirror Write Consistency (MWC) is turned ON, logical partitions that might be inconsistent if the system or the volume group is not shut down properly are identified. When the volume group is varied back online, this information is used to make logical partitions consistent. This is referred to as active MWC.
When a logical volume is using active MWC, then requests for this logical volume are held within the scheduling layer until the MWC cache blocks can be updated on the target physical volumes. When the MWC cache blocks have been updated, the request proceeds with the physical data Write operations. Only the disks where the data actually resides must have these MWC cache blocks written to it before the Write can proceed.
When active MWC is being used, system performance can be adversely affected. Adverse affects are caused by the overhead of logging or journaling that a Write request in which a Logical Track Group (LTG) is active. The allowed LTG sizes for a volume group are 128 K, 2456 K, 512 K, and 102 4K, with the default size as 128 K.
Note: To have an LTG size greater than 128 K, the disks contained in the volume group must support I/O requests of this size from the disk's strategy routines. The LTG is a contiguous block contained within the logical volume and is aligned on the size of the LTG. All I/Os must be no larger than an LTG and must be contained in a single LTG. This overhead is for mirrored Writes only.
It is necessary to guarantee data consistency between mirrors only if the system or volume group crashes before the Write to all mirrors has been completed. All logical volumes in a volume group share the MWC log. The MWC log is maintained on the outer edge of each disk. Locate the logical volumes that use Active MWC at the outer edge of the disk so that the logical volume is in close proximity to the MWC log on disk.
When MWC is set to passive, the volume group logs that the logical volume has been opened. After a crash when the volume group is varied on, an automatic force sync of the logical volume is started. Consistency is maintained while the force sync is in progress by using a copy of the read recovery policy that propagates the blocks being read to the other mirrors in the logical volume. This policy is only supported on the BIG volume group type.
When MWC is turned OFF, the mirrors of a mirrored logical volume can be left in an inconsistent state in the event of a system or volume group crash. There is no automatic protection of mirror consistency. Writes outstanding at the time of the crash can leave mirrors with inconsistent data the next time the volume group is varied on. After a crash, any mirrored logical volume that has MWC turned OFF should perform a forced sync before the data within the logical volume is used. For example,
syncvg -f -l LTVname
An exception to forced sync is logical volumes whose content is only valid while the logical volume is open, such as paging spaces.
A mirrored logical volume is no different from a non-mirrored logical volume with respect to a Write. When LVM completely finishes with a Write request, the data has been written to all the drive(s) below LVM. The outcome of the Write is unknown until LVM issues an iodone on the Write. After this is complete, no recovery after a crash is necessary. Any blocks being written that have not been completed (iodone) when a machine crashes should be checked and rewritten whether or not they are mirrored, regardless of the MWC setting.
Because a mirrored logical volume is no different from a non-mirrored logical volume, there is no such thing as latest data. All applications that care about data validity need to determine the validity of the data of outstanding or inflight writes that did not complete before the volume group or system crashed, whether or not the logical volume was mirrored.
Active and passive MWC make mirrors consistent only when the volume group is varied back online after a crash by picking one mirror and propagating that data to the other mirrors. These MWC policies do not keep track of the latest data. active MWC only keeps track of LTGs currently being written, therefore MWC does not guarantee that the latest data will be propagated to all the mirrors. Passive MWC makes mirrors consistent by going into a propagate-on-read mode after a crash. It is the application above LVM that has to determine the validity of the data after a crash. From the LVM prospective, if the application always reissues all outstanding Writes from the time of the crash, the possibly inconsistent mirrors will be consistent when these Writes finish, (as long as the same blocks are written after the crash as were outstanding at the time of the crash).
Note: Mirrored logical volumes containing either JFS logs or file systems must be synchronized after a crash either by forced sync before use, by turning MWC on, or turning passive MWC on.
The inter-disk allocation policy specifies the number of disks on which the physical partitions of a logical volume are located. The physical partitions for a logical volume might be located on a single disk or spread across all the disks in a volume group. Two options in the mklv and chlv commands are used to determine inter-disk policy:
If you select the minimum inter-disk setting (Range = minimum), the physical partitions assigned to the logical volume are located on a single disk to enhance availability. If you select the maximum inter-disk setting (Range = mimum), the physical partitions are located on multiple disks to enhance performance. The allocation of mirrored copies of the original partitions is discussed in the following section.
For nonmirrored logical volumes, use the minimum setting to provide the greatest availability (access to data in case of hardware failure). The minimum setting indicates that one physical volume contains all the original physical partitions of this logical volume if possible. If the allocation program must use two or more physical volumes, it uses the minimum number, while remaining consistent with other parameters.
By using the minimum number of physical volumes, you reduce the risk of losing data because of a disk failure. Each additional physical volume used for a single physical copy increases that risk. A nonmirrored logical volume spread across four physical volumes is four times as likely to lose data because of one physical volume failure than a logical volume contained on one physical volume.
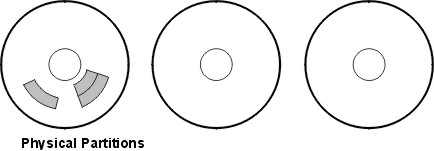
The following figure illustrates a minimum inter-disk allocation policy.
Figure 6-3. Minimum Inter-Disk Allocation Policy. This illustration shows three disks. One disk contains three physical partitions; the others have no physical partitions.
The maximum setting, considering other constraints, spreads the physical partitions of the logical volume as evenly as possible over as many physical volumes as possible. This is a performance-oriented option, because spreading the physical partitions over several disks tends to decrease the average access time for the logical volume. To improve availability, the maximum setting is only used with mirrored logical volumes.
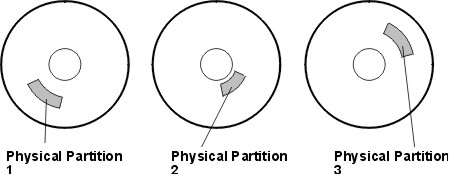
The following figure illustrates a maximum inter-disk allocation policy.
Figure 6-4. Maximum Inter-Disk Allocation Policy. This illustration shows three disks, each containing one physical partition.
These definitions are also applicable when extending or copying an existing logical volume. The allocation of new physical partitions is determined by your current allocation policy and where the existing used physical partitions are located.
The allocation of a single copy of a logical volume on disk is fairly straightforward. When you create mirrored copies, however, the resulting allocation is somewhat complex. The figures that follow show minimum maximum and inter-disk (Range) settings for the first instance of a logical volume along with the available Strict settings for the mirrored logical volume copies.
For example, if there are mirrored copies of the logical volume, the minimum setting causes the physical partitions containing the first instance of the logical volume to be allocated on a single physical volume, if possible. Then, depending on the setting of the Strict option, the additional copy or copies are allocated on the same or on separate physical volumes. In other words, the algorithm uses the minimum number of physical volumes possible, within the constraints imposed by other parameters such as the Strict option, to hold all the physical partitions.
The setting Strict = y means that each copy of the logical partition is placed on a different physical volume. The setting Strict = n means that the copies are not restricted to different physical volumes.
Note: If there are fewer physical volumes in the volume group than the number of copies per logical partition you have chosen, set Strict to n. If Strict is set to y, an error message is returned when you try to create the logical volume.
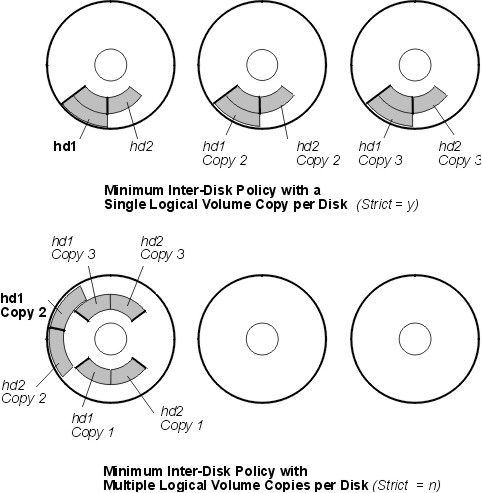
The following figure illustrates a minimum inter-disk allocation policy with differing Strict settings:
Figure 6-5. Minimum Inter-Disk Policy/Strict. This illustration shows that if Strict is equal to Yes, each copy of the logical partition is on a different physical volume. If Strict is equal to No, all copies of the logical partitions are on a single physical volume.
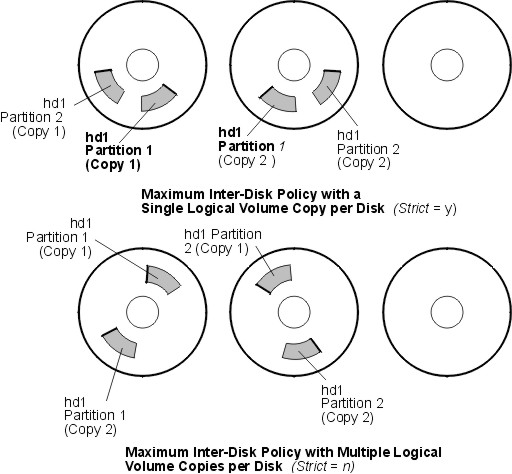
The following figure illustrates a maximum inter-disk allocation policy with differing Strict settings:
Figure 6-6. Maximum Inter-Disk Policy/Strict. This illustration shows that if Strict is equal to Yes, each copy of a partition is on a separate physical volume. If Strict is equal to No, all copies are on a single physical volume.
The closer a given physical partition is to the center of a physical volume, the lower the average seek time because the center has the shortest average seek distance from any other part of the disk.
The file system log is a good candidate for allocation at the center of a physical volume because it is used by the operating system so often. At the other extreme, the boot logical volume is used infrequently and therefore is allocated at the edge or middle of the physical volume.
The general rule is that the more I/Os, either absolutely or during the running of an important application, the closer to the center of the physical volumes the physical partitions of the logical volume needs to be allocated. This rule has two important exceptions:
The intra-disk allocation policy choices are based on the five regions of a disk where physical partitions can be located. The five regions are:
The edge partitions have the slowest average seek times, which generally result in longer response times for any application that uses them. The center partitions have the fastest average seek times, which generally result in the best response time for any application that uses them. There are, however, fewer partitions on a physical volume at the center than at the other regions.
If you select inter-disk and intra-disk policies that are not compatible, you might get unpredictable results. The system assigns physical partitions by allowing one policy to take precedence over the other. For example, if you choose an intra-disk policy of center and an inter-disk policy of minimum, the inter-disk policy takes precedence. The system places all of the partitions for the logical volume on one disk if possible, even if the partitions do not all fit into the center region. Make sure you understand the interaction of the policies you choose before implementing them.
If the default options provided by the inter- and intra-disk policies are not sufficient for your needs, consider creating map files to specify the exact order and location of the physical partitions for a logical volume.
You can use Web-based System Manager, SMIT, or the -m option for the mklv command to create map files.
Note: The -m option is not permitted with disk striping.
For example, to create a ten-partition logical volume called lv06 in the rootvg in partitions 1 through 3, 41 through 45, and 50 through 60 of hdisk1, you could use the following procedure from the command line.
lspv -p hdisk1
to verify that the physical partitions you plan to use are free to be allocated.
hdisk1:1-3 hdisk1:41-45 hdisk1:50-60
The mklv command allocates the physical partitions in the order that they appear in the map file. Be sure that there are sufficient physical partitions in the map file to allocate the entire logical volume that you specify with the mklv command. (You can list more than you need.)
mklv -t jfs -y lv06 -m /tmp/mymap1 rootvg 10
Striped logical volumes are used for large sequential file systems that are frequently accessed and performance-sensitive. Striping is intended to improve performance.
NOTE:
- You can import an AIX 3.2 created volume group into an AIX 4.1 system, and you can import an AIX 4.1 volume group into an AIX 3.2. system, provided striping has not been applied. Once striping is put onto a disk, its importation into AIX 3.2 is prevented. The current implementation of mksysb does not restore any striped logical volume after the mksysb image is restored.
- A volume group with a mirrored striped logical volume cannot be imported into a version older than AIX 4.3.3.
- A dump space or boot logical volume is not striped.
To create a 12-partition striped logical volume called 1v07 in VGName with a stripe size of 16 KB across hdisk1, hdisk2, and hdisk3, you would enter the following:
mklv -y lv07 -S 16K VGName 12 hdisk1 hdisk2 hdisk3
To create a 12-partition striped logical volume called 1v08 in VGName with a stripe size of 8 KB across any three disks within VGName, you would enter the following:
mklv -y lv08 -S 8K -u 3 VGName 12
For more information on how to improve performance by using disk striping, see AIX 5L Version 5.1 Performance Management Guide.
Using the write-verify option causes all Write operations to be verified by an immediate follow-up Read operation to check the success of the Write. If the Write operation is not successful, you get an error message. This policy enhances availability but degrades performance because of the extra time needed for the Read. You can specify the use of a write-verify policy on a logical volume either when you create it using the mklv command or later by changing it with the chlv command.