You can define your own symbols to display geometric text for use with the graPHIGS APIscreen See Chapter 9. "Character Sets and Fonts Provided by the API" for a detailed explanation of CSIDs and fonts.
If you are defining fonts to be used on the IBM 5080, be sure to read "IBM 5080 Character Set Restrictions"screen
Your application can specify a character string to be displayed in geometric text. The graPHIGS API, in processing that character string, accesses two files to get the information necessary to interpret and display the text:
Your application program specifies CSIDs as integer values. The API divides CSID values into the following ranges:
The graPHIGS API provides many character set files and symbol files. You should not modify the IBM-supplied files. The installation of new releases causes the IBM-supplied files to be loaded to your installation disk, replacing the current files. New releases may contain corrections to errors or may provide additional fonts for existing character sets. If you modify the IBM-supplied files, you will lose your changes when the next release is installed. If you wish to modify the IBM-supplied character set and symbol files, copy them to separate files and use the copies to create user-defined character sets and fonts. IBM-supplied, double-byte character sets are exceptions to this rule.
For your convenience, the Personal graPHIGS product on the RS/6000 provides a basic font editor. The font editor allows you to create and modify characters in font files. The font editor is found in the directory:
/usr/lpp/graPHIGS/clients/fonteditorSee the README files in the directory for instructions on use of the font editor.
Assignable code points of a character set must be within
the ranges shown in the following table:
Table 98. Range of Assignable Code Points
| Assigned Byte | Code Point in EBCDIC | Code Point in ASCII |
|---|---|---|
| Single-byte of SBCS | X'40' to X'FE' | X'20' to X'FF' |
| Both bytes of DBCS | X'40' to X'FE' | X'20' to X'FF' |
| Both bytes of Unicode DBCS | X'00' to X'FF' | X'00' to X'FF' |
If you create your own character sets, you should provide the translation tables for EBCDIC and ASCII. Though your current application needs may be only for one encoding (such as EBCDIC), your future requirements may use the character set and font files in other environments. Specifying both the EBCDIC and ASCII organizations and the corresponding translations will eliminate rework of your files for such a conversion. If your character set doesn't follow a standard EBCDIC or ASCII definition, you could assign the same code point for both the EBCDIC and ASCII tables.
If you are creating your own font within a character set, ensure that you define a symbol for every character in the set you are working with, and that the character maintains its meaning.
If you wish to add or delete characters, move characters to different code points, or change the meaning of the code point, create a new character set for the font.
Double-byte character sets (DBCS) have user-definable subareas of the code point range where you may create additional characters.
The ranges of these
sub-areas are shown in the following table:
Table 99. User-assignable Code Point Ranges for Kanji, Hangul, Chinese, and Unicode
| Encoding | First byte | Second byte |
|---|---|---|
| Kanji (EBCDIC) | X'69' to X'7F' | X'40' to X'FE' |
| Kanji (ASCII) | X'F0' to X'F9' | X'20' to X'FF' |
| Hangul (ASCII) | X'8F' to X'A0' | X'20' to X'FF' |
| Hangul (EBCDIC) | X'D4' to X'DD' | X'40' to X'FE' |
| Traditional Chinese (ASCII) | X'DB' to X'FB' | X'40' to
X'7E'
X'80' to X'FC' |
| Simplified Chinese (ASCII) | X'A2'
X'A2' X'A2' X'A2' X'A4' X'A5' X'A6' X'A6' X'A7' X'A7' X'A8' X'A8' X'A9' X'A9' X'AA' to X'AF' X'D7' X'F8' to X'FD' X'FE' |
X'A1' to X'B0'
X'E3' to X'E4' X'EF' to X'F0' X'FD' to X'FE' X'F4' to X'FE' X'F7' to X'FE' X'B9' to X'C0' X'D9' to X'FE' X'C2' to X'D0' X'F2' to X'FE' X'BB' to X'C4' X'EA' to X'FE' X'A1' to X'A3' X'F0' to X'FE' X'A1' to X'FE' X'FA' to X'FE' X'A1' to X'FE' X'A1' to X'DF' |
| Unicode | X'E0' to X'F7' | X'00' to X'FF' |
The graPHIGS API supplies two methods for you to define characters for the user-definable ranges of double-byte character sets:
Alter the IBM-supplied character set files by adding characters in the user-definable range. You must also update the two translation tables for translating between EBCDIC and ASCII, except for the Unicode character set which has no translation table. These altered IBM files then become unique to your application.
Create a new character set and font files for just the user-assignable code points you wish to define. These files may then be combined with the IBM-supplied files by the graPHIGS APIscreen This method has particular advantages pertaining to the graPHIGS API shell and nucleus organization. (See The graPHIGS Programming Interface: Understanding Concepts for discussions of the shell-nucleus organization.) With this method, all applications running to a particular nucleus can share the common IBM-supplied files, yet each application can have a unique set of files defining some set of the user-assignable codepoints installed on the application's disk.
The IBM-defined double-byte files should be installed on the nucleus font disk. The user-defined files should be on the application's disk.
To use a double-byte character set on a workstation:
When receiving the activate font request, the graPHIGS API nucleus searches in the associated font directory for the font files. If the nucleus finds the user-defined files in the associated font directory, then it searches for the IBM-defined files on the nucleus' disk. It then activates the font and includes both the IBM ranges and the user-defined ranges. Therefore, each application can ensure that the activated font includes its own user-defined codepoints. The IBM-defined font is always taken from the nucleus font disk and the application need not send it from the shell side.
When creating user-defined characters for Traditional Chinese, be aware that the graPHIGS API processes code points as IBM-927 double-byte encoding, not the AIX Traditional Chinese IBM-EUC encoding.
This section explains the relationship between the information in a symbol file and the display of a text string. The text string appearance is defined by the font characteristics specified in the symbol file and the geometric text attributes.
For example, the alignment attribute allows your application to specify a positioning line on which to position the entire text extent rectangle relative to the text position (see "Text Extent Rectangle" for an explanation of the text extent rectangle). The positioning line is specified by the attribute and the value of the positioning line is in the symbol file. The graPHIGS API uses both the symbol file description and the attributes to control text position, alignment, height and width. The following sections describe the symbol file contents and illustrate how it relates to geometric text attributes. Refer to The graPHIGS Programming Interface: Understanding Concepts for details about the geometric text attributes.
Note: For illustration purposes, all diagrams contain proportional sized character boxes.
The shape of each symbol representing a character is defined in its own local, two dimensional, Cartesian font coordinate system. The intersection of the x- and y-axes in this coordinate system is called the font coordinate origin.
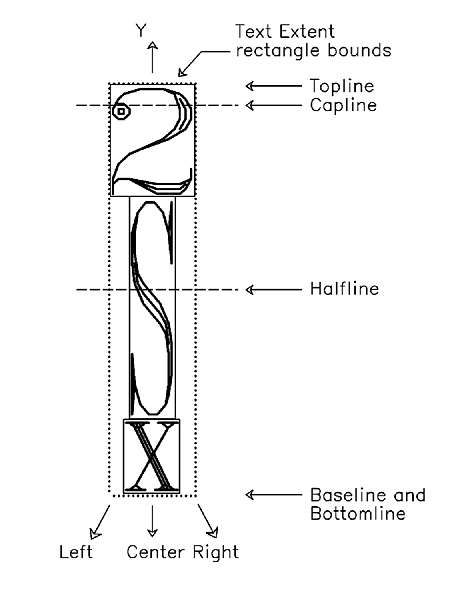
Each character in a font coordinate system has a character box composed of the character body (topline, bottomline, rightline and leftline), baseline, halfline, capline and centerline. Character box characteristics are defined in relation to the font coordinate origin (the intersection of the x- and y-axes). The following diagram describes the character box about a local font coordinate system.
Figure 56. Character box about a local font coordinate system
The rectangle that bounds the character box, called the character body, is defined by four values named TOP, BOT, RIGHT and LEFT screen Each value is a signed value relative to the local coordinate system origin.
A font contains character box definitions where the baseline, halfline, capline and centerline are fixed per font. The baseline and centerline correspond respectively to the x- and y-axes of a character's local font coordinate system. The capline is specified per font and the halfline is midway between the baseline and the capline.
Fixed-sized fonts have the character body, TOP, BOT, RIGHT and LEFT specified once for the entire font. Proportionally-spaced fonts also have a character body dimension for each character.
The character body is used to position a character relative to other characters within a text string. The TOP, BOT, RIGHT and LEFT values are used to position adjacent characters with their bodies touching. For example, in a text string with text path right and no additional space between character bodies, the right edge of each character body will be co-linear with the left edge of the character body to its immediate right.
Characters within a text string are aligned along each character's baseline or centerline. All the origins are co-linear along a line that is parallel to the text path direction.
Characters are defined within the character body boundaries but they may exceed the boundaries. For example, a kern or oversized character like the integral sign may exceed the boundaries. All character positioning is performed on the character body not on the character extents, which may exceed the character body.
The text extent rectangle is the minimum rectangle which completely encloses all the character extent rectangles in a string. The character extent rectangle has dimensions similar to the character body, TOP, BOT, RIGHT and LEFT screen Conceptually, there is a character extent rectangle for each character. The character extent rectangle and the character body will be defined by the same parameters.
Calculation of the vertical and horizontal components of the text extent rectangle involves calculating the maximum dimensions in a text string. For example, the text extent for path right or left is the left-most leftline, right-most rightline, maximum topline and the minimum bottomline.
Figure 57. Location of a text extent rectangle
------ . . . . . . . . . .
| | -------------
| |------| |
| |------| |
| | -------------
| | .<---Text extent rectangle
------ . . . . . . . . . .
Text alignment is calculated relative to the text extent rectangle. The horizontal component of text alignment has three values: RIGHT_ALIGN, LEFT_ALIGN and CENTER screen The vertical component has five values: TOP, CAP, HALF, BASE and BOTTOM screen
Notice where these values lie when you specify a horizontal alignment, as shown in the figure below.
Figure 58. Alignment of a text string specified with path right or left
When your application specifies a vertical alignment ( Figure 59), notice:
Figure 59. Alignment of a text string specified with path up or down
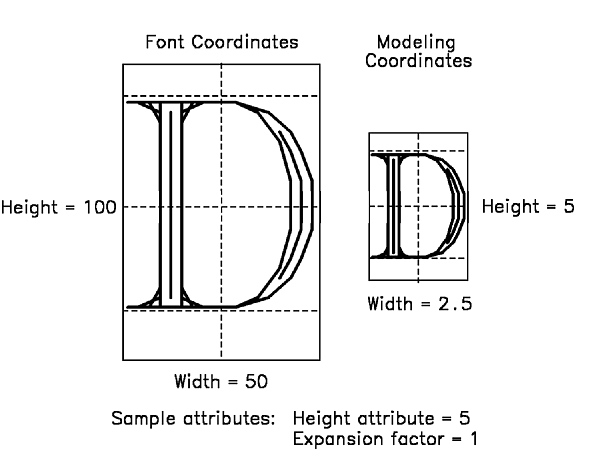
The graPHIGS API displays text strings by mapping the local font coordinates of each symbol to modeling coordinates. The application specifies the character height in modeling coordinates. The height of the font in the font coordinate system is mapped to the height specified in modeling coordinates. The ratio between the font height to the modeling height is multiplied by the expansion factor and the font width produce the width. The following diagram illustrates the relationship between local font coordinates and modeling coordinates.
Figure 60. Relationship between Local Font Coordinates and Modeling Coordinates.
This section describes the file organization used to map a code point to its drawing controls.
Each single-byte character set (SBCS) and font combination consists of two files, the SBCS file and the Symbol Definition file.
The SBCS file contains ASCII and EBCDIC code point indexes that map code points to symbol IDs. (The symbol ID serves as a generic name for a symbol that is independent of an encoding scheme such as ASCII or EBCDIC.) The Symbol Definition file contains a symbol ID table that maps symbol IDs to their drawing controls.
The complete process from code point to drawing controls begins with the code point, which maps to a symbol ID that in turn identifies a location where the drawing controls for that symbol ID are found. The following diagram shows this flow in relationship to the files.
SBCS File Symbol Definition File
Header----------- Header -----------
| | | |
| | | |
------------- |---------| |---------|
| ASCII Code| | |------ Symbol| |
| Point |----->| | | ID Index| |
------------- ASCII| | v | |
Index| | | | |
-------------- |---------| |---------->| |
| EBCDIC Code| | | ^ |---------|
| Point |---->| |-----| Symbol| |
-------------- | | Defs | |
BCDIC| | | |
Index| | | |
| | | |
----------- -----------
Single-Byte SBCS and Symbol Definition Files
Single-byte ASCII and EBCDIC code points
having the same symbol ID will map to the same drawing controls.
Each double-byte character set (DBCS) and font combination consists of 2 files, the DBCS file and the Symbol Definition file.
The DBCS file contains ASCII and EBCDIC code point indexes that map code points to symbol IDs. (The symbol ID serves as a generic name for a symbol that is independent of an encoding scheme such as ASCII or EBCDIC.) The Symbol Definition file contains a symbol ID table that maps symbol IDs to their drawing controls.
The double-byte character set file has two levels of in-direction. The first byte of the code point ('B1') is used as an index into a table, called the B1 table. The B1 table contains the addresses of tables indexed by the second byte of the code point ('B2'), called the B2 tables. The entry in the B2 table contains a symbol ID.
The complete process from code point to drawing controls begins with the code point, which maps to a symbol ID (using two levels of in-direction), that in turn identifies a location where the drawing controls for that symbol ID are found.
The following diagram shows this flow in relationship to the files.
DBCS File Symbol Definition Files
Header----------- Header-----------
| | | |
| | | |
|---------| |---------|
ASCII | | Symbol| |
ASCII Code Point B1 Index | | ID Index| |
| | | |
|------------------------>| |--- | |
----------- | | | | |
| B1 | B2 | ----------- | | |
----------- ----------- | | |
| | | | | |
| ASCII | | | | |
| B2 Index | | | | |
| ----------- | | |
| . | | |
| . | | |
| ----------- | | |
| | |<-- | |
|-------------------> | |----------------->| |
ASCII | | | | |
B2 Index | | | |---------|
----------- | | |
----------- | Symbol| |
EBCDIC Code Point EBCDIC | | | Defns| |-----
B1 Index | | ^ | | |
|-------------------------->| |--- | | | |
----------- | | | | | | |
| B1 | B2 | | | | | | | |
----------- ----------- | | | | |
| ----------- | | | | |
|-------------------->| |<-- | | | |
EBCDIC| | | | | |
B2 Index | |------- | | |
----------- | | |
. | |<----
----------- | |
EBCDIC | | | |
B2 Index | | | |
| | | |
----------- | |
-----------
Double-Byte DBCS and Symbol Definition Files
Double-byte ASCII and EBCDIC Code Points
having the same symbol ID maps to the same drawing controls.
The Single-Byte Character Set (SBCS) files and the Double-Byte Character Set (DBCS) files are unique per character set. The information in these files varies depending on whether it is for a single-byte or double-byte character set.
The SBCS files and the DBCS files each have a fixed-length header which is located at the beginning of the file and contains control information. Header information includes:
Variable data in the SBCS files and the DBCS files begins immediately after the header. The graPHIGS API accesses this part of the file by using the offsets and ranges in the header. The variable data may include:
The Symbol Definition files are unique per font within a character set.
The file contains a fixed length header which includes:
Variable data in the Symbol Definition files begins just after the header. The graPHIGS API accesses this part of the file by using the offsets and ranges in the header. The variable data includes:
When the graPHIGS API receives a request to activate (Activate Font - GPACFO) or load (Load Font - GPLDFO) a character set and font, it attempts to load either the SBCS or DBCS file and the Symbol Definition file. The filenames that the software expects for these files differ according to your environment: AIX, MVS, or VM.
Use Table 100 and Table 101 to ensure that your filenames are correct for your environment and/or the load option for the GPLDFO subroutine.
Each character set identifier
has one SBCS/DBCS file that contains the
ASCII/EBCDIC index and the translate tables.
The graPHIGS API attempts to load the SBCS/DBCS file
according to the naming convention in
Table 100screen
For double-byte character sets,
see
Table 101screen
The graPHIGS API also attempts to load
the user-defined subareas of
double-byte character sets,
according to the naming convention in
Table 101screen
Table 100. SBCS/DBCS File-Naming Convention on AIX, MVS, and VM
| VM | MVS | AIX |
| 1.Filename 'AFMcc ' | 2.PDS member'AFMcc ' | 3.Filename 'afmcc.sym' |
| 4.Filetype 'AFMSYMBL' | 5.DDNAME 'AFMSYMBL' cc = Character set identifier in hexadecimal; | |
| Note: See "Identifying a Character Set"screen | ||
Table 101. SBCS/DBCS Naming Convention on AIX, MVS, and VM for User-Defined DBCS File for User Range of DBCS 128 - 132
| VM | MVS | AIX |
| 1.Filename 'UDFcc ' | 2.PDS member'UDFcc ' | 3.Filename 'udfccscreen |
| 4.Filetype 'AFMSYMBL' | 5.DDNAME 'AFMSYMBL' | |
| Note:
cc = Character set identifier in hexadecimal; See "Identifying a Character Set"screen CSID 130 is only supported in the AIX environment. | ||
If the SBCS/DBCS file loads successfully, then the graPHIGS API
attempts to load the respective Symbol Definition
file according to the naming convention in
Table 102screen
For IBM-supplied double-byte symbol files,
the API also attempts to load the
user-defined range,
according to the naming convention in
Table 103screen
Table 102. Symbol Definition File Naming Conventions on AIX, MVS, and VM
| VM | MVS | AIX |
| 1.Filename 'AFMccff ' | 2.PDS member'AFMccff ' | 3.Filename 'afmccffscreen |
| 4.Filetype 'AFMSYMBL' | 5.DDNAME 'AFMSYMBL' | |
| Note:
cc = Character set identifier in hexadecimal; See "Identifying a Character Set" ff = Font identifier in hexadecimal | ||
Table 103. Naming Convention on AIX, MVS, and VM for User-Defined Symbol Definition File for User Range of DBCS 128 - 132
| VM | MVS | AIX |
| 1.Filename 'UDFccff ' | 2.PDS member'UDFccff ' | 3.Filename 'udfccffscreen |
| 4.Filetype 'AFMSYMBL' | 5.DDNAME 'AFMSYMBL' | |
| Note:
cc = Character set identifier in hexadecimal; See "Identifying a Character Set" ff = Font identifier in hexadecimal CSID 130 is only supported in the AIX environment. | ||
This section provides tabular summaries of file format and notes on the contents of these three files:
The internal file format is binary on all environments. On VM and MVS, all files are four hundred byte fixed length records.
Refer to the tables for information on byte offset, field length, field content, or brief descriptions of these characteristics.
The notes following each table, field content descriptions, give you more details on the content of the fields in the file, along with special considerations, restrictions, and usage.
Note:
A "V" in the length field indicates variable-length.
Caution:
All reserved fields in the font files must be
initialized to zero.
Table 104. Single-Byte Character Set File Format
| Byte | Field Length | Field Content | Description |
|---|---|---|---|
| 0 | 1 | VERSION | Font file version identifier |
| 1 | 1 | RESERVED | |
| 2 | 1 | FLAGS | Bits are on to indicate:
|
| 3 | 1 | RESERVED | |
| 4 | 4 | LENGTH | Total length of file, all fields |
| 8 | 2 | ASCII DEF | ASCII default character code |
| 10 | 1 | ASCII CP0 | Starting ASCII character code |
| 11 | 1 | ASCII CPN | Last ASCII character code |
| 12 | 4 | ASCII CHAR INDEX OFFSET | Offset of ASCII CHAR INDEX |
| 16 | 4 | ASCII --> EBCDIC OFFSET | Offset of ASCII to EBCDIC translation table |
| 20 | 2 | EBCDIC DEF | EBCDIC default character code |
| 22 | 1 | EBCDIC CP0 | Starting EBCDIC character code |
| 23 | 1 | EBCDIC CPN | Last EBCDIC character code |
| 24 | 4 | EBCDIC CHAR INDEX OFFSET | Offset of EBCDIC CHAR INDEX |
| 28 | 4 | EBCDIC --> ASCII OFFSET | Offset of EBCDIC to ASCII translation table |
| 32 | LENGTH DATA | ||
| V | ASCII CHAR INDEX | 2 byte symbol IDs | |
| EBCDIC CHAR INDEX | 2 byte symbol IDs | ||
| ASCII --> EBCDIC | Table to translate from ASCII to EBCDIC 1 byte character codes | ||
| EBCDIC --> ASCII | Table to translate from EBCDIC to ASCII 1 byte character codes | ||
Table 105. ASCII <--> EBCDIC Translation
| Field Length | Field Content | Description |
|---|---|---|
| 1 | CP0 | Starting character code |
| 1 | CPN | Last character code |
| V | CODE POINTS | 1 byte code points |
Table 106. Double-Byte Character Set File Format
| Byte | Field Length | Field Content | Description |
|---|---|---|---|
| 0 | 1 | VERSION | Font file version identifier |
| 1 | 1 | RESERVED | |
| 2 | 1 | FLAGS | Bits are on to indicate:
|
| 3 | 1 | RESERVED | |
| 4 | 4 | LENGTH | Total length of file, all fields |
| 8 | 2 | ASCII DEF | ASCII default character code |
| 10 | 1 | ASCII B10 | Starting character code for first byte of double-byte character code |
| 11 | 1 | ASCII B1N | Last character code for first byte of double-byte character code. |
| 12 | 4 | ASCII B1 TABLE OFFSET | Offset of B1 table |
| 16 | 4 | ASCII --> EBCDIC OFFSET | Offset of ASCII to EBCDIC translation table |
| 20 | 2 | EBCDIC DEF | EBCDIC default character code |
| 22 | 1 | EBCDIC B10 | Starting character code for first byte of double-byte character code |
| 23 | 1 | EBCDIC B1N | Last character code for first byte of double-byte character code. |
| 24 | 4 | EBCDIC B1 TABLE OFFSET | Offset of B1 table |
| 28 | 4 | EBCDIC --> ASCII OFFSET | Table to translate from EBCDIC to ASCII |
| 32 | START OF VARIABLE LENGTH DATA | ||
| V | ASCII B1 TABLE | Fullword offset for each B2 table | |
| ASCII B2 TABLES | B2 table definition | ||
| EBCDIC B1 TABLE | Fullword offset for each B2 table | ||
| EBCDIC B2 TABLES | B2 table definition | ||
| ASCII --> EBCDIC | Table to translate from ASCII to EBCDIC | ||
| EBCDIC --> ASCII | Table to translate from EBCDIC to ASCII | ||
The first six fields of the DBCS file are similar to the SBCS file. Refer to "Field Content Description", the description for SBCS, for more information.
Table 107. B2 ASCII and EBCDIC Format
| Field Length | Field Content | Description |
|---|---|---|
| 1 | B20 | Starting character code for 2nd byte of double-byte character code |
| 1 | B2N | Last char code for 2nd byte of double-byte character code |
| V | CHAR INDEX | 2-byte symbol IDs |
Table 108. B1 (ASCII to EBCDIC) Addresses
| Field Length | Field Content | Description |
|---|---|---|
| 1 | B10 | Starting character code |
| 1 | B1N | Last character code |
| 2 | RESERVED | |
| V | OFFSET | 4 byte offset to start of the B2 table relative to the start of the variable data area. The offset for undefined character codes should be zero. |
Table 109. B2 (ASCII to EBCDIC) Code Points
| Field Length | Field Content | Description |
|---|---|---|
| 1 | B20 | Starting character code for 2nd byte of double-byte character code |
| 1 | B2N | Last char code for 2nd byte of double-byte character code |
| V | CODE POINTS | 2-byte code points |
Table 110. Symbol Definition File Format
| Byte | Field Length | Field Content | Description |
|---|---|---|---|
| 0 | 1 | VERSION | Font file version identifier |
| 1 | 2 | FLAGS | Bits are to indicate what optional information is
present for each symbol:
|
| 3 | 1 | CAP | CAP line, must be greater than 0 |
| 4 | 1 | NTOP | TOP of nominal symbol box |
| 5 | 1 | NBOT | BOT of nominal symbol box |
| 6 | 1 | NRIGHT | RIGHT of nominal symbol box |
| 7 | 1 | NLEFT | LEFT of nominal symbol box |
| 8 | 2 | CTOP | TOP of symbol clip box |
| 10 | 2 | CBOT | BOT of symbol clip box |
| 12 | 2 | CRIGHT | RIGHT of symbol clip box |
| 14 | 2 | CLEFT | LEFT of symbol clip box |
| 16 | 2 | ASYM0 | Starting symbol ID for range of symbol IDs within this font |
| 18 | 2 | ASYMN | Last symbol ID for range of symbol IDs within this font |
| 20 | 4 | LENGTH | Total length of structure, including field |
| 24 | 4 | SID INDEX OFFSET | Offset of the symbol ID index |
| 28 | 4 | SYMBOL DEFNS OFFSET | Offset to the start of the symbol definitions |
| 32 | START OF VARIABLE LENGTH DATA | ||
| V | SID INDEX | Symbol ID index | |
| SYMBOL DEFNS | Symbol definitions | ||
| Field Length | Field Content | Description |
|---|---|---|
| 4 | OFFSET | Offset to locate symbol. The offset is relative to the start of the symbol definitions, e.g., the first symbol definition after the index has offset zero |
| 2 | LENGTH | Number of bytes in symbol definition |
| 1 | FLAGS | Flags are on to indicate:
|
| 1 | RESERVED | |
| 1 | TOP | Top of character body2 |
| 1 | BOTTOM | Bottom of character body2 |
| 1 | RIGHT | Right of character body2 |
| 1 | LEFT | Left of character body2 |
| Notes: 1
Each character does not have to be
filled. The flags field indicates whether this
character is filled.
If the interface does not support filled fonts, then the
characters are not filled.
See
The graPHIGS Programming Interface: Understanding Concepts,
for more information.
2 The fields TOP, BOTTOM, RIGHT, LEFT are only present if bit 0 of the FLAGS field of the Symbol Definition file header is set ON. | ||
| Symbol Definitions |
|---|
X BYTE Y BYTE
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
s x x x x x x 1 s y y y y y y b
| ----------- | ----------- |
| | | | -- relative move/
| | | | draw flag:
| | | | 0 is draw
| | | | 1 is move
| | | |
| | | -- relative to previous y
-----------------------------sign bit
|
-- relative to previous x |
For the 5080, the following restrictions apply:
The FONTLIST PROCOPT allows the user to list the user-defined character sets which will be used for a specific workstation type or connection identifier.
The API will determine the size of these character sets at Open Workstation time in order to allocate the needed space for them. All of the character sets supplied by IBM will be automatically available on the 5080 workstation, whether or not this PROCOPT is specified. See the FONTLIST PROCOPT description in "FONTLIST (Character Font List)"screen
If your application uses the Japanese Language Feature for Kanji, PCSs are allocated in the 5080 for the requested wards. These count towards the maximum of 48, but are undetectable by the API. Thus, in this case you must ensure that the number of PCSs simultaneously active in the 5080 does not exceed 48.
{kind=link}
{kind=link}
{kind=link}
{kind=link}