The Japanese Input Method (JIM) is a sophisticated input method that provides Japanese input. The features include:
For internal processing, the JIM uses the IBM-932 code set. However, it supports any code set, such as IBM-eucJP, that can be converted from IBM-932.
The Japanese code sets consist of three character groups:
Katakana and Hiragana consist of about 50 characters each and form the set of phonetic characters referred to as Kana. All of the sounds in the Japanese language can be represented in Kana.
Kanji is a set of ideographs. A simple concept can be represented by a single Kanji character, while more complicated meanings can be formed with strings of Kanji characters. There are several thousand Kanji characters.
The Japanese also use the Roman alphabet. Called Romaji, the Roman alphabet consists of 26 characters. It is used mostly in technical and professional environments to represent technical vocabulary that does not exist in Japanese. A typical sentence is usually a mixture of Katakana, Hiragana, Kanji, Romaji, numbers, and other characters.
The Japanese Industrial Standard (JIS) specifies about 7000 Kanji characters processed by computer systems. Japanese products made by this manufacturer support all of the standard characters and more. Input of the characters is accomplished through:
The following special keys appear on the 106-key Japanese keyboard to allow for these conversions:
| Special Japanese Keys | ||
| Key Function | Key Name | Description of Function |
| KKC Non-conversion key | muhenkan | Leaves Kana characters as is. |
| KKC Conversion key | henkan | Converts Kana to Kanji. |
| KKC All Candidates key | zenkouho | Shows all possible Kanji representatives. |
| RKC Romaji Mode key | romaji | Toggles RKC on and off. |
| Hiragana Shift key | hiragana | Becomes Hiragana shift state. |
| Katakana Shift key | katakana | Becomes Katakana shift state. |
| Romaji Shift key | eisu | Becomes Romaji shift state. |
Note: Shift states are maintained until you press another shift key. The initial state is Romaji.
The Japanese Input Method's (JIM) KKC technology is based on the fact that every Kanji character or set of Kanji characters has a phonetic sound or sounds that can be expressed by Katakana or Hiragana characters.
It is much easier to input Hiragana or Katakana characters than Kanji characters. The JIM analyzes the phonetic values of the Hiragana and Katakana characters to determine the best Kanji-character equivalent. Such phonetic analysis depends on the dictionary and tables provided to the JIM.
The JIM has three different modes that can be used to control the input processing:
Allows invocation of alphanumeric, Katakana, or Hiragana modes.
Inputs in Zenkaku (full-width) or Hankaku (half-width) mode.
Inputs Kana directly or invoke the pre-edit composing mode to input Kana with a combination of alphabetic characters. The pre-editing facility allows processing of characters before they are committed to the application.
When the keyboard mapping mode is alphanumeric and the character size mode is Hankaku, the JIM maps keys to Romaji characters. This mode combination is known as the "English" mode. Pre-editing is not needed in English mode and cannot be invoked regardless of the RKC mode setting. The other mode combinations may initiate pre-editing and characters generated in these modes are not ASCII.
The following keys are used to perform Kana-to-Kanji conversion by the JIM.
| Keysym | Keyboard Mapping |
| Katakana | Katakana shift |
| Eisu_toggle | Alphanumeric shift |
| Hiragana | Hiragana shift |
| Keysym | Character Size |
| Zenkaku_Hankaku | Full-width or Half-width toggle |
| Hankaku | Half-width |
| Zenkaku | Full-width |
| Keysym | RKC on/off |
| Alt-Hiragana | Enables/Disables Romaji-to-Kana conversion |
| Romaji | *The same effect |
* Keysyms unique to the manufacturer
The following keys are also used when the JIM is pre-editing a Kanji string.
| Keysym | Kanji pre-edit |
| Muhenkan | Non-conversion - commit Kana |
| Henkan | Conversion - get next candidate |
| Kanji | Same as Henkan |
| BunsetsuYomi | *Moves back a phrase |
| MaeKouko | *Moves to previous candidate |
| LeftDouble | *Moves cursor two characters left |
| RightDouble | *Moves cursor two characters right |
| ErInput | *Discards the current pre-edit string |
| Keysym | Auxiliary pre-edit |
| Alt-Henkan | All candidates |
| Touroku | Runtime registration |
| ZenKouho | *All candidates (the same effect) |
| KanjiBangou | *Kanji Number Input |
| HenkanMenu | *Changes conversion mode |
* Keysyms unique to the manufacturer
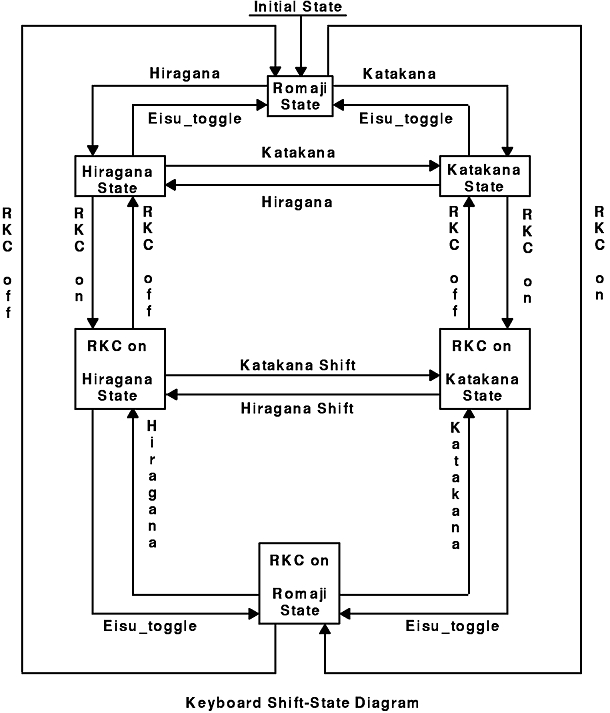
There are 3 possible keyboard mapping states: Alphanumeric (Romaji), Katakana and Hiragana. Each state is invoked by a keysym that acts as a locking shift key. The keysyms are Katakana, Eisu_toggle, and Hiragana shift.
When one of these keysyms is pressed, keyboard mapping enters the state associated with the key. This state is maintained until one of the other keysyms is pressed. The initial shift state is Eisu_toggle, which can be changed by customization.
When you invoke the Hiragana or Katakana state, each key is mapped to a phonetic character within the respective character set. For example, if you press q, a Hiragana character pronounced "ta" is produced during Hiragana shift state, a Katakana character pronounced "ta" is produced during Katakana shift state, or a Romaji "q" is produced during Eisu_toggle shift state. On Japanese IBM keyboards, the tops of keys show all three symbols.
Also, when keyboard mapping is in Hiragana state, the input method is automatically put into a composing pre-editing mode where each Hiragana character can be converted into a Kanji character. See "Kanji Pre-edit" for more information.
Some keys have two Hiragana or Katakana characters assigned. For example, the 7 key has large and small Hiragana characters both having the pronunciation "ya". These characters are not upper and lower case equivalents of each other since Kanji, Hiragana, and Katakana do not have uppercase and lowercases. The small characters are used to express special phonetic sounds. These characters can be distinguished by using the shift key.
A subset of the Japanese character set is represented in both full-width and half-width. Kanji ideographic characters are usually full-width. The phonetic and ASCII characters have both full-width and half-width representations. The user controls character size by pressing the Zenkaku_Henkaku keysym which toggles between full-width and half-width.
For users familiar with alphanumeric keyboards, it is easier to key in the phonetic sounds rather than the Hiragana or Katakana characters. The JIM provides Romaji-to-Kana conversion (RKC), allowing the user to type in the phonetic sounds of Hiragana or Katakana characters on an alphanumeric keyboard.
The following diagram shows the flow of a key event:
When operating in Romaji-To-Kana conversion mode, you must follow two steps to produce Kanji characters. First, the user inputs Hiragana characters by typing their Romaji phonetic characters. In this step, you produce a Hiragana character by typing 1 to 3 Romaji alphabetic keys that compose the phonetic sound of the Hiragana character. Second, convert the Hiragana characters to Kanji characters by pressing the Henkan key. Many Kanji characters may be associated with a single phonetic phrase. The Henkan key displays the most likely Kanji candidates. Repeated pressing of the Henkan key displays all the additional candidates.
For example, when entering the Kanji characters for the phonetic sound "k-a-n-j-i", you must do two things:
You may now press the keys that spell "kanji". As each phonetic sound is completed, a Hiragana character is displayed.
The Hiragana character is displayed with visual feedback to indicate that the JIM is composing in a pre-edit state. The character is underlined and shown in reverse video. This feedback facility is known as a callback. See "Using Callbacks" for more information.
To convert the Hiragana character within the pre-edit string to a Kanji character, press the Henkan key. The most likely candidate associated with the phonetic Hiragana sound is displayed. Pressing this key repeatedly shows other candidates.
During the composition process, the pre-edit string is partitioned into segments that can be considered Kanji words. Once a string of kana characters is converted into a candidate, it is treated as one of these convertible segments. While the pre-edit string is displayed, the JIM uses the cursor key and other keys to manipulate the string.
To commit the pre-edit string to the program, the user presses the Enter key. In this case, the Enter key code itself is not sent to the program, only the string.
The Muhenkan keysym can also be used to turn off pre-edit and commit the Hiragana or Katakana character directly to the program.
The Keyboard Shift-State Transition diagram depicts the shift state transition and the interaction of the RKC mode key with the shift states.
There are 4 types of auxiliary areas within the JIM.
A Kana-to-Kanji conversion operation on a string of Hiragana or Katakana characters can yield from one to a hundred Kanji candidates. At worst, you would have to press the conversion key more than a hundred times to get the correct Kanji character.
In such cases, it is more convenient to find the correct character by requesting the All Candidates menu with the ZenKouho or the Alt-Henkan keysym. This menu appears if the current target (a Kanji word that the cursor is pointing to in the pre-edit area) has several alternative candidates associated with it. The menu contains multiple candidates for selection. The All Candidates menu disappears when the Reset keysym is pressed, the Enter key is pressed, or a candidate is selected.
A Kanji Number Input dialog prompts the user to select the Kanji character by entering 3 to 5 digits. The digits represent the code of the character. Online dictionaries allow a user to search for the code. The ordering formats for these dictionaries vary. For example, one dictionary lists codes by phonetic sound. Another dictionary orders codes by the number of strokes used to compose the character. The KanjiBangou keysym invokes this menu. The menu is terminated with either the Reset or Return keysym.
The HenkanMenu keysym invokes the Conversion Mode menu. Four items are displayed for selection. The most important items are the word-conversion mode and phrase-conversion mode. Make a selection by choosing a number and pressing the Return keysym. This menu is terminated when either a selection is made or the Reset keysym is pressed.
A runtime registration dialog prompts the user to input a Kana string and a Kanji string for registering the mapping of the strings in the user dictionary. Once the pair is registered, the JIM can use it as a conversion candidate. The menu is terminated with the Escape or Reset keysym.
The presentation of menus depends on the interface environment in which the JIM is operating. For example, some interfaces support scrolling menus that use the Page Down and Page Up keys. Discussion of these interfaces is outside the scope of this document.
ja_JP.IBM-eucJP@DoubleByte.imkeymap
Ja_JP.IBM-932@DoubleByte.imkeymap
The JIM uses the keysyms in the XK_KATAKANA, XK_LATIN1, and XK_MISCELLANY groups.
| XK_BunsetsuYomi | 0x1800ff05 | Back a phrase to Yomi |
| XK_MaeKouho | 0x1800ff04 | Previous candidate |
| XK_ZenKouho | 0x1800ff01 | All candidates. |
| XK_KanjiBangou | 0x1800ff02 | Kanji number input. |
| XK_HenkanMenu | 0x1800ff03 | Changes conversion mode. |
| XK_LeftDouble | 0x1800ff06 | Moves cursor two characters left. |
| XK_RightDouble | 0x1800ff07 | Moves cursor two characters right. |
| XK_LeftPhrase | 0x1800ff08 | Reserved for future use. |
| XK_RightPhrase | 0x1800ff09 | Reserved for future use. |
| XK_ErInput | 0x1800ff0a | Discards the current pre-edit string |
| XK_Resetreset | 0x1800ff0b | Reset |
The preceding keysyms are unique to the input method of this system.
| ShiftMask | 0x01 |
| LockMask | 0x02 |
| ControlMask | 0x04 |
| Mod1Mask (Left-Alt) | 0x08 |
| Mod2Mask (Right-Alt) | 0x10 |
| Kana | 0x20 |
| Romaji | 0x40 |
Understanding the ISO Code Sets in AIX Kernel Extensions and Device Support Programming Concepts.
{kind=link}
{kind=link}