The following explains the benefits of writing multi-threaded programs. Major improvements of threads programming are:
Threads do have some limitations and cannot be used for some special purposes which still require multi-processed programs.
There are two main advantages for using parallel programming instead of serial programming techniques:
Traditionally, multiple single-threaded processes have been used to achieve parallelism, but some programs can benefit from a finer level of parallelism. Multi-threaded processes offer parallelism within a process and share many of the concepts involved in programming multiple single-threaded processes.
Programs are often modeled as a number of distinct parts interacting with each other to produce a desired result or service. A program can be implemented as a single, complex entity that performs multiple functions among the different parts of the program. A more simple solution consists of implementing several entities, each entity performing a part of the program and sharing resources with other entities.
By using multiple entities, a program can be separated according to its distinct activities, each having an associated entity. These entities do not have to know anything about the other parts of the program except when they exchange information. In these cases, they must synchronize with each other to ensure data integrity.
Threads are well-suited entities for modular programming. Threads provide simple data sharing (all threads within a process share the same address space) and powerful synchronization facilities (such as mutexes and condition variables).
The following common software models can easily be implemented with threads.
All these models lead to modular programs. Models may also be combined to efficiently solve complex tasks.
These models can apply to either traditional multi-process solutions, or to single process multi-thread solutions, on multi-threaded systems such as AIX. In the following descriptions, the word entity refers to either a single-threaded process or to a single thread in a multi-threaded process.
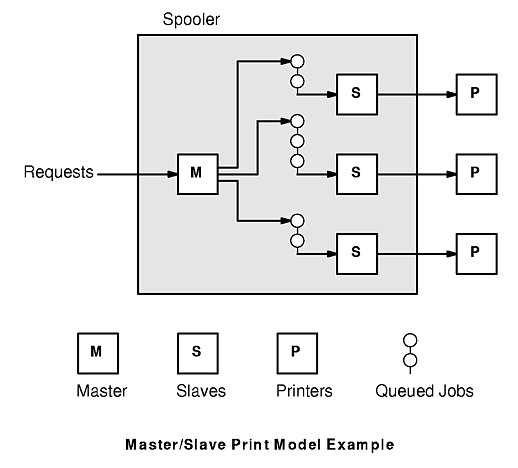
In the master/slave (sometimes called boss/worker) model, a master entity receives one or more requests, then creates slave entities to execute them. Typically, the master controls how many slaves there are and what each slave does. A slave runs independently of other slaves.
An example of this model is a print job spooler controlling a set of printers. The spooler's role is to ensure that the print requests received are handled in a timely fashion. When the spooler receives a request, the master entity chooses a printer and causes a slave to print the job on the printer. Each slave prints one job at a time on a printer, handling flow control and other printing details. The spooler may support job cancellation or other features which require the master to cancel slave entities or reassign jobs. The following figure illustrates this model.
In the divide-and-conquer (sometimes called simultaneous computation or work crew) model, one or more entities perform the same tasks in parallel. There is no master entity; all entities run in parallel independently.
An example of a divide-and-conquer model is a parallelized grep command implementation, which could be done as follows. The grep command first establishes a pool of files to be scanned. It then creates a number of entities. Each entity takes a different file from the pool and searches for the pattern, sending the results to a common output device. When an entity completes its file search, it obtains another file from the pool or stops if the pool is empty.
The producer/consumer (sometimes called pipelining) model is typified by a production line. An item proceeds from raw components to a final item in a series of stages. Usually a single worker at each stage modifies the item and passes it on to the next stage. In software terms, an AIX command pipe, such as the cpio command, is a good example of a this model.
The following figure illustrates a typical producer/consumer model. In this example, the Reader entity reads raw data from standard input and passes it to the processor entity, which processes the data and passes it to the writer entity, which writes it to standard output. Parallel programming allows the activities to be performed concurrently: the writer entity may output some processed data while the reader entity gets more raw data.
Multi-threaded programs can improve performance in many ways compared to traditional parallel programs using multiple processes. Furthermore, higher performance can be obtained on multiprocessor systems using threads.
Managing threads, that is creating threads and controlling their execution, requires fewer system resources than managing processes. Creating a thread, for example, only requires the allocation of the thread's private data area, usually 64KB, and two system calls. Creating a process is far more expensive, because the entire parent process addressing space is duplicated.
The threads library API is also easier to use than the one for managing processes. Programmers should think about the six ways of calling the exec subroutine. Thread creation requires just one syntax: the pthread_create subroutine.
Inter-thread communication is far more efficient and easier to use than inter-process communication. Because all threads within a process share the same address space, they need not use shared memory. Shared data should just be protected from concurrent access using mutexes or other synchronization tools.
Synchronization facilities provided by the threads library allow easy implementation of flexible and powerful synchronization tools. These tools can easily replace traditional inter-process communication facilities, such as message queues. Note that pipes can be used as an inter-thread communication path.
On a multiprocessor system, multiple threads can concurrently run on multiple CPUs. Therefore, multi-threaded programs can run much faster than on a uniprocessor system. They will also be faster than a program using multiple processes, because threads require fewer resources and generate less overhead. For example, switching threads in the same process can be faster, especially in the M:N library model where context switches can often be avoided. Finally, a major advantage of using threads is that a single multi-threaded program will work on a uniprocessor system, but can naturally take advantage of a multiprocessor system, without recompiling.
Multi-threaded programming is useful for implementing parallelized algorithms using several independent entities. However, there are some cases where multiple processes should be used instead of multiple threads.
Many operating system identifiers, resources, states, or limitations are defined at the process level and, thus, are shared by all threads in a process. For example, user and group IDs and their associated permissions are handled at process level. Programs that need to assign different user IDs to their programming entities need to use multiple processes, instead of a single multi-threaded process. Other examples include file system attributes such as the current working directory, and the state and maximum number of open files. Multi-threaded programs may not be appropriate if these attributes are better handled independently. For example, a multi-processed program can let each process open a large number of files without interference from other processes.
Performance Overview of the AIX CPU Scheduler.
{kind=link}
{kind=link}