 View figure.
View figure.
To understand the value of the IBM Recoverable Virtual Shared Disk component, consider a system without it. The virtual shared disk function lets all nodes in the system partition access a given disk, even though that specific disk is physically attached to only one node. If the server node should fail, access to the disk is lost until the server node is rebooted by the administrator.
By using the IBM Recoverable Virtual Shared Disk component and twin-tailed disks or disk arrays, you can allow a secondary node to take over the server function from the primary node when certain types of failure occur.
A twin-tailed disk is a disk or group of disks that are attached to two nodes of an SP. For recoverability purposes, only one of these nodes serves the disks at any given time. The secondary or backup node provides access to the disks if the primary node fails, is powered off, or if you need to change the server node temporarily for administrative reasons. Both must be in the same system partition.
A twin-tailed volume group is a volume group that contains disks that are accessible to two nodes. Both nodes must be in the same system partition.
The IBM Recoverable Virtual Shared Disk component automatically manages your virtual shared disks by detecting error conditions, such as node failures, adapter failures, and disk failures (EIO errors), and then switching access to the disk from the primary node to the secondary node so that your application can continue to operate normally. The IBM Recoverable Virtual Shared Disk component also allows you to cut off access to virtual shared disks from certain nodes and to dynamically change the server node (using the graphical user interface or the fencevsd and vsdchgserver commands, respectively).
When your applications exploit the IBM Recoverable Virtual Shared Disk component, you can recover more easily from node failures and have continuous access to the data on the twin-tailed disks.
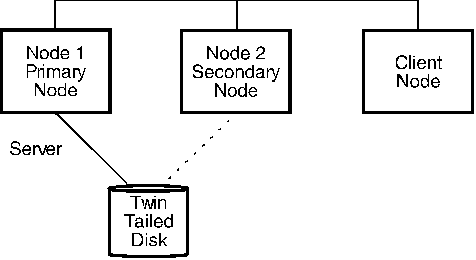
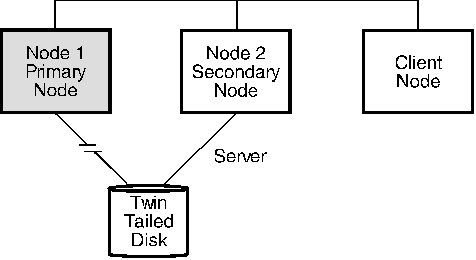
The following three figures show a simple system with one twin-tailed recoverable virtual shared disk configuration. Figure 4 shows the basic configuration. The primary node is the server of information on the disk. In Figure 5, the secondary node is acting as the server following a failure of the primary node.
Figure 4. Simplified View of a Twin-tailed Disk
View figure.
Figure 5. The Secondary Node Serves after a Primary Node Failure
 View figure.
View figure.
In Figure 6, the primary node is again the server and has automatically taken over the disk from the secondary node.
Figure 6. The Primary Node Is the Server Again after Recovery
View figure.
Recovery is transparent to applications that have been enabled for recovery -- there is no disruption of service, only a slight delay while takeover occurs. The IBM Recoverable Virtual Shared Disk component provides application programming interfaces, including recovery scripts and C programs, so you can enable your applications to be recoverable.
Recovery is very similar to the twin-tailed disk example. The differences are:
Note: On a "reintegration" where a failed node is coming back, that failed node must still varyonvg.