{kind=link}
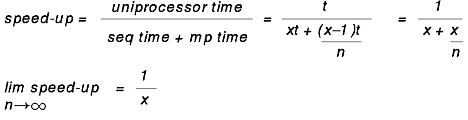
The effect of additional processors on performance is dominated by certain characteristics of the specific workload being handled. The following sections discuss those critical characteristics and their effects.
Multiprogramming operating systems like AIX running heavy workloads on fast computers like the RS/6000 give our human senses the impression that several things are happening simultaneously. In fact, many demanding workloads do not have large numbers of dispatchable threads at any given instant, even when running on a single-processor system where serialization is less of a problem. Unless there are always at least as many dispatchable threads as there are processors, one or more processors will be idle part of the time.
The number of dispatchable threads is:
The total number of threads in the system, minus the number of threads that are waiting for I/O, minus the number of threads that are waiting for a shared resource, minus the number of threads that are waiting for the results of another thread, minus the number of threads that are sleeping at their own request.
A workload can be said to be multiprocessable to the extent that it presents at all times as many dispatchable threads as there are processors in the system. Note that this does not mean simply an average number of dispatchable threads equal to the processor count. If the number of dispatchable threads is zero half the time and twice the processor count the rest of the time, the average number of dispatchable threads will equal the processor count, but any given processor in the system will be working only half the time.
Increasing the multiprocessability of a workload involves one or both of:
These solutions are not independent. If there is a single, major system bottleneck, increasing the number of threads of the existing workload that pass through the bottleneck will simply increase the proportion of threads waiting. If there is not currently a bottleneck, increasing the number of threads may create one.
All of these factors contribute to what is called the scalability of a workload. Scalability is the degree to which workload throughput benefits from the availability of additional processors. It is usually expressed as the quotient of the throughput of the workload on a multiprocessor divided by the throughput on a comparable uniprocessor. For example, if a uniprocessor achieved 20 requests per second on a given workload and a four-processor system achieved 58 requests per second, the scaling factor would be 2.9. That workload is highly scalable. A workload that consisted exclusively of long-running, compute-intensive programs with negligible I/O or other kernel activity and no shared data might approach that level. Most real-world workloads would not. Scalability is very difficult to estimate. Whenever possible, scalability assumptions should be based on measurements of authentic workloads.
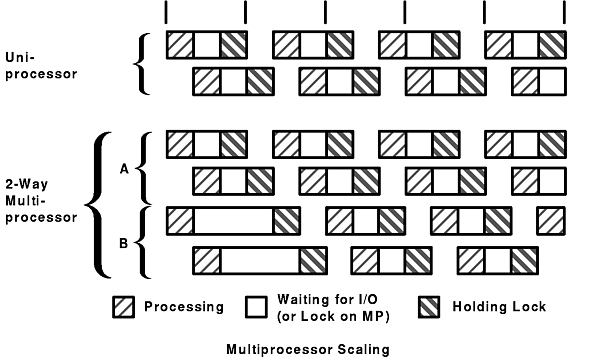
The figure "Multiprocessor Scaling" illustrates the problems of scaling. The workload consists of a series of commands. Each command is about one-third normal processing, one-third I/O wait, and one-third processing with a lock held. On the uniprocessor, only one command can actually be processing at a time, regardless of whether or not the lock is held. In the time interval shown (five times the standalone execution time of the command), the uniprocessor handles 7.67 of the commands.
On the multiprocessor, there are two processors to handle program execution, but there is still only one lock. For simplicity, all of the lock contention is shown affecting processor B. In the period shown, the multiprocessor handles 14 commands. The scaling factor is thus 1.83. We stop at two processors because more would not change the situation. The lock is now in use 100% of the time. In a four-way multiprocessor, the scaling factor would be 1.83 or less.
Real programs are seldom as symmetrical as the commands in the illustration. Remember, too, that we have only taken into account one dimension of contention--locking. If we had included cache-coherency and processor-affinity effects, the scaling factor would almost certainly be lower yet.
The point of this example is that workloads often cannot be made to run faster simply by adding processors. It is also necessary to identify and minimize the sources of contention among the threads.
Some published benchmark results imply that high levels of scalability are easy to achieve. Most such benchmarks are constructed by running combinations of small, CPU-intensive programs that use almost no kernel services. These benchmark results represent an upper bound on scalability, not a realistic expectation.
A multiprocessor can only improve the execution time of an individual program to the extent that the program can run multithreaded. There are several ways to achieve parallel execution of parts of a single program:
Unless one or more of these techniques is used, the program will run no faster in a multiprocessor system than in a comparable uniprocessor. In fact, since it may experience more locking overhead and delays due to being dispatched to different processors at different times, it may be significantly slower.
Even if all of the applicable techniques are exploited, the maximum improvement is limited by a rule that has been called Amdahl's Law:
If a fraction x of a program's uniprocessor execution time, t, can only be processed sequentially, the improvement in execution time in an n-way multiprocessor over execution time in a comparable uniprocessor (the speed-up) is given by the equation:
As an example, if 50% of a program's processing must be done sequentially, and 50% can be done in parallel, the maximum response-time improvement is less than a factor of 2 (in an otherwise-idle 4-way multiprocessor, at most 1.6)