Diskless systems potentially offer excellent processor power coupled with low cost, low noise and space requirements, and centralized data management. As tantalizing as these advantages seem, diskless workstations are not the best solution for every desktop. This section sheds some light on the workings of AIX diskless workstations, the kinds of loads they present to their servers, and the resulting performance of different kinds of programs. Much of the NFS background in this section also applies to serving requests from workstations with disks. The following subsections provide more information on diskless systems:
In a system with local disks (also referred to as a diskful system), the operating system and the programs needed to do the most basic functions are contained on one or more local disks. When the system is started, the operating system is loaded from local disk. When the system is fully operational, the files accessible to users are usually on local disk. The software that manages the local disks is the journaled file system (JFS).
In a diskless system, the operating system must be booted from a server using bootstrap code that is in the diskless machine's read-only storage. The loading takes place over a local area network: an Ethernet or a Token Ring. When the system is fully operational, the files accessible to users are located on disks on one or more server systems.
The primary mechanism used by diskless workstations to access files is the Network File System (NFS). NFS makes remote files seem to be located on the diskless system. NFS is not exclusive to diskless systems. Diskful systems can also mount remote file systems. Diskless systems, or diskful systems that depend on servers for files, are usually called clients.
Normally, several diskless clients are attached to each server, so they contend for the server's resources. The difference in performance between otherwise identical diskless and diskful systems is a function of file systems (NFS versus JFS), the network speed, and the server resources.
The Network File System lets multiple clients access remotely mounted data in a consistent manner. It provides primitives for basic file-system functions such as create, read, write, and remove. NFS also provides support for directory operations such as making a directory, removing a directory, reading and setting attributes, and path-name lookup.
The protocol used by NFS is stateless, that is, no request to the server depends on any previous request. This adds to the robustness of the protocol. It also introduces performance problems. Consider the case of writing a file. As the file is written, the modified data is either in the client memory or on the server. The NFS protocol requires that data written from the client to the server must be committed to nonvolatile storage, normally disk, before the write operation is considered complete. That way, if the server crashes, the data the client had written can be recovered after system restart. Data that was being written and was not committed to the disk would be rewritten by the client to the server until the write was successful. Because NFS does not allow write buffering in the server, each NFS write requires one or more synchronous disk writes. For example, if a new file of 1 byte is written by the client, the completion of that write would entail three disk I/Os on the server. The first would be the data itself. The second would be the journal record, a feature of JFS to maintain file-system integrity. The third is a flush of the file-allocation data. Because disks can only write 50 to 100 times a second, total write throughput is limited by the number of and type of disks on the server system.
Read and write requests used by AIX clients are 4096 bytes or 8192 bytes in length. These requests generally require more server resources to process than other request types.
Because remote files and file attributes may be cached in the memory of the client, the NFS protocol provides mechanisms for ensuring that the client version of file-system information is current. For example, if a 1-byte file is read, the file data will be cached as long as the space it occupies in the client is not needed for another activity. If a program in the client reads the file again later, the client ensures that the data in the local copy of the file is current. This is accomplished by a Get Attribute call to the server to find out if the file has been modified since it was last read.
Path-name resolution is the process of following the directory tree to a file. For example, opening the file /u/x/y/z normally requires examining /u, x, y, and z in that order. If any component of the path does not exist, the file cannot exist as named. One of NFS's caches is used to cache frequently used names, reducing the number of requests actually going to the server.
Obviously, the server receives some mix of read or write and smaller requests during any time interval. This mix is hard to predict. Workloads that move large files frequently will be dominated by read/write requests. Support of multiple diskless workstations will tend to generate a larger proportion of small NFS requests, although it depends greatly on the workload.
To better understand the flow of NFS requests in a diskless client, let's look at the Korn shell execution of the trivial C program:
#include <stdio.h>
main()
{
printf("This is a test program\n");
}
The program is compiled, yielding an executable named a.out . Now if the PATH environment variable is /usr/bin:/usr/bin/X11:. (the period representing the current working directory is at the end of the path) and the command a.out is entered at the command line, the following sequence of operations occurs:
| Request type | Component | Bytes Sent and Received | |
| 1 | NFS_LOOKUP | usr (called by statx) | (send 178, rcv 70) |
| 2 | NFS_LOOKUP | bin | |
| 3 | NFS_LOOKUP | a.out | (Not found) |
| 4 | NFS_LOOKUP | usr (called by statx) | |
| 5 | NFS_LOOKUP | bin | |
| 6 | NFS_LOOKUP | X11 | (send 174, rcv 156) |
| 7 | NFS_LOOKUP | a.out (Not found) | (send 174, rcv 70) |
| 8 | NFS_LOOKUP | . (called by statx) | (send 174, rcv 156) |
| 9 | NFS_LOOKUP | . | |
| 10 | NFS_LOOKUP | a.out | (send 178, rcv 156) |
| 11 | NFS_LOOKUP | . (called by accessx) | |
| 12 | NFS_LOOKUP | a.out | |
| 13 | NFS_GETATTR | a.out | |
| 14 | NFS_LOOKUP | . | |
| 15 | NFS_LOOKUP | a.out | (send 170, rcv 104, send 190, rcv 168) |
| 16 | fork | ||
| 17 | exec | ||
| 18 | NFS_LOOKUP | usr | |
| 19 | NFS_LOOKUP | bin | |
| 20 | NFS_LOOKUP | a.out (Not found) | (send 178, rcv 70) |
| 21 | NFS_LOOKUP | usr | |
| 22 | NFS_LOOKUP | bin | |
| 23 | NFS_LOOKUP | X11 | |
| 24 | NFS_LOOKUP | a.out (Not found) | (send 178, rcv 70) |
| 25 | NFS_LOOKUP | . | |
| 26 | NFS_LOOKUP | a.out | |
| 27 | NFS_OPEN | (send 166, rcv 138) | |
| 28 | NFS_GETATTR | a.out | |
| 29 | NFS_ACCESS | (send 170, rcv 104, send 190, rcv 182) | |
| 30 | NFS_GETATTR | a.out | |
| 31 | FS_GETATTR | a.out | |
| 32 | NFS_READ | a.out (Read executable) | (send 178, rcv 1514, rcv 1514, rcv 84) |
| 33 | NFS_GETATTR | a.out | |
| 34 | NFS_LOOKUP | usr (Access library) | |
| 35 | NFS_LOOKUP | lib | |
| 36 | NFS_LOOKUP | libc.a | |
| 37 | NFS_READLINK | libc.a | (send 166, rcv 80) |
| 38 | NFS_LOOKUP | usr | |
| 39 | NFS_LOOKUP | ccs | |
| 40 | NFS_LOOKUP | lib | |
| 41 | NFS_LOOKUP | libc.a | |
| 42 | NFS_OPEN | libc.a | (send 166, rcv 124) |
| 43 | NFS_GETATTR | libc.a | |
| 44 | NFS_ACCESS | libc.a | (send 170, rcv 104, send 190, rcv 178) |
| 45 | NFS_GETATTR | libc.a | |
| 46 | NFS_GETATTR | libc.a | |
| 47 | NFS_CLOSE | libc.a | |
| 48 | _exit |
If the PATH were different, the series of NFS operations would be different. For example, a PATH of .:/usr/bin:/usr/bin/X11: would allow the program a.out to be found much sooner. The negative side of this PATH would be that most commands would be slower to execute since most of them are in /usr/bin . Another fast way to execute the program would be by entering ./a.out , since no lookup is needed on the executable (although library resolution still is needed). Adding a lot of seldom-used directories to the PATH will slow down command execution. This applies to all environments, but is particularly significant in diskless environments.
Another factor to consider in program development is minimizing the number of libraries referenced. Obviously, the more libraries that need to be loaded, the slower the program execution becomes. Also the LIBPATH environment variable can affect the speed of program loading, so use it carefully if at all.
National Language Support can also be a factor in program execution. The above example was run in the "C" locale, the most efficient. Running in other locales can cause additional overhead to access message catalogs.
At first look, the NFS activity for a small program seems intimidating. Actually, the performance of the above example is quite acceptable. Remember that the path resolution for file accesses also takes place in JFS file systems, so the total number of operations is similar. The NFS cache ensures that not all NFS operations result in network traffic. Finally, the latency for network operations is usually small, so the aggregate increase in elapsed time for the command is not great--unless the server itself is overloaded.
AIX diskless systems perform paging via the NFS protocol. Paging is the process by which working storage such as program variables may be written to and read from disk. Paging occurs when the sum of the memory requirements of the processes running in a system is larger than the system memory. (See "Performance Overview of the Virtual Memory Manager (VMM)".)
Paging is a mixed blessing in any system. It does allow memory to be overcommitted, but performance usually suffers. In fact, there is a narrow range of paging that will allow acceptable response time in a workstation environment.
In the diskless environment, paging is particularly slow. This is a result of the NFS protocol forcing writes to disk. In fact, one can expect each page out (write) operation to be at best two to three times slower than on a diskful system. Because of paging performance, it is important that diskless systems contain enough memory that the application mix being executed does not normally page. (See "Memory-Limited Programs".)
AIXwindows-based desktop products encourage behavior that can lead to periods of intense paging in systems with inadequate memory. For example, a user may have two programs running in different windows: a large spreadsheet and a database. The user recalculates a spreadsheet, waits for the calculation to complete, then switches windows to the database and begins a query. Although the spreadsheet is not currently running, it occupies a substantial amount of storage. Running the database query also requires lots of storage. Unless real memory is large enough to hold both of these programs, the virtual-memory pages of the spreadsheet are paged out, and the database is paged in. The next time the user interacts with the spreadsheet, memory occupied by the database must be paged out, and the spreadsheet must be paged back in. Clearly user tolerance of this situation will be determined by how often windows are switched and how loaded the server becomes.
Several AIX services can be used to measure client-server workloads. The number of NFS requests processed by a system is available via nfsstat. This command details the NFS-request counts by category. The netstat command allows analysis of total packet counts and bytes transferred to a network device. The iostat command details processor utilization and disk utilization, which are useful for measuring server systems. Finally, the AIX trace facility allows the collection of very detailed performance data.
Capacity planning for diskless networks is often complicated by the "burstiness" of client I/O requests--the characteristic pattern of short periods of high request rates interspersed with longer periods of low request rates. This phenomenon is common in systems where people act as the primary drivers of applications.
The capacity, or number of clients supported by a server and network for a particular workload, is determined by request statistics and end-user requirements. Several questions should be asked.
Sometimes remote execution is more appropriate for running large applications. By running the application on the server, via a remote window, the client is able to take advantage of the memory of the server system and the fact that multiple instances of the application from different clients could share pages of code and document files. If the application is run in the client, swapping behavior as described previously would dramatically affect response time. Other uses, such as large, disk-intensive make or cp operations, can also benefit by moving the application closer to the hard disks.
When configuring networks and servers for diskless clients, application measurement should be performed whenever possible. Don't forget to measure server processor utilization and disk utilization. They are more likely to present bottlenecks than either Ethernet or 16Mb Token-Ring networks.
The capacity of a client/server configuration may be thought of in terms of supply and demand. The supply of resources is constrained by the type of network and the server configuration. The demand is the sum of all client requirements on the server. When a configuration produces unacceptable performance, improvement can be obtained by changing the client demand or by increasing the server supply of resource.
Utilization is the percentage of time a device is in use. Devices with utilizations greater than 70% will see rapidly increasing response times because incoming requests have to wait for previous requests to complete. Maximum acceptable utilizations are a trade-off of response time for throughput. In interactive systems, utilizations of devices should generally not exceed 70-80% for acceptable response times. Batch systems, where throughput on multiple job streams is important, can run close to 100% utilization. Obviously, with mixtures of batch and interactive users, care must be taken to keep interactive response time acceptable.
Client tuning can involve any combination of:
If a client contains insufficient memory, the end result is working-storage paging. This can be detected by looking at the output of vmstat -s. If a client experiences continual working-storage paging, adding memory to the client will almost always improve the client's performance.
The number of block I/O daemons (biods) configured on a client limits the number of outstanding NFS read and write requests. In a diskless system without NFS explicitly activated, only a few biods are available. If NFS is activated, the number increases. Normally, the default number of biods available with NFS activated is sufficient for a diskless workstation.
Both the Ethernet and Token Ring device drivers have parameters defining the transmit queue size and receive queue size for the device. These parameters can have performance implications in the client. See the section on "Tuning Other Layers to Improve NFS Performance".
Adding a disk to a diskless machine should not be considered heresy. In fact, marketing studies indicate that diskless systems are usually upgraded to having a disk within a year of purchase. Adding a disk does not necessarily nullify the chief advantage of diskless systems--centralized file maintenance. A disk may be added for paging only. This is usually called a dataless system. Other combinations exist. For example a disk may contain both paging space and temporary file space.
The network bandwidth of Ethernet is nominally 10 megabits/second. In practice, contention among the users of the Ethernet makes it impossible to use the full nominal bandwidth. Considering that an IBM SCSI disk can provide up to 32 megabits/second, it is alarming to consider a number of clients sharing about one-fourth the bandwidth of a disk. This comparison is only valid, however, for applications that do sequential disk I/O. Most workloads are dominated by random I/O, which is seek and rotational-latency limited. Since most SCSI disks have sustainable throughputs of 50 - 85 random I/O operations per second, the effective random I/O rate of a disk is 2 - 3 megabits/second. Therefore, an Ethernet bandwidth is roughly equivalent to about two disks doing random I/O. There is a lesson here. Applications that do sequential I/O on large files should be run on the system to which the disks are attached, not on a diskless workstation.
Although the maximum transfer unit (MTU) of a LAN can be changed using SMIT, diskless workstations are limited to using the default sizes.
Server configuration involves:
The server CPU processing power is significant because all server requests require CPU service. Generally, the CPU processing required for read and write requests is significantly more than for other requests.
Server disk configuration is usually the first bottleneck encountered. One obvious tuning hint is to balance the disk I/O, so that no one disk's utilization is much greater than the others. Another is to maximize the number of disks. For example, two 400MB disks will provide almost twice the random I/Os per second of a single 857MB disk. Additionally, with AIX it is possible to place a journal log on another device. By doing this, the multiple-write NFS sequence is improved as follows:
By not having the journal on the file disk, one or two potentially long disk-seek operations are avoided. (If the file and the journal log were on the same lightly loaded disk, the accessor would be continually seeking back-and-forth between file area and journal log.)
The number of instances of the NFS daemon (nfsd) running on the server limits the number of NFS requests that the server can be executing concurrently. The default number of nfsds is only 8, which is probably insufficient for all but low-end servers. The number of nfsds started at each boot can be changed via smit nfs (Network File System (NFS) -> Configure NFS on This System).
The server memory size is significant only for NFS read operations. Since writes cannot be cached, memory size has no effect on write performance. On the other hand, assuming that some files are used repetitively, the larger the server memory, the higher the probability that a read can be satisfied from memory, avoiding disk I/O. Avoiding disk I/O has the threefold benefit of reducing disk utilization, improving response time for the read, and decreasing server CPU utilization. You can observe server disk activity using iostat. The following cues may indicate that additional memory could improve the performance of the server:
As in the client, both the Ethernet and Token-Ring device drivers have limits on the number of buffers available for sending data. See "Tuning Other Layers to Improve NFS Performance".
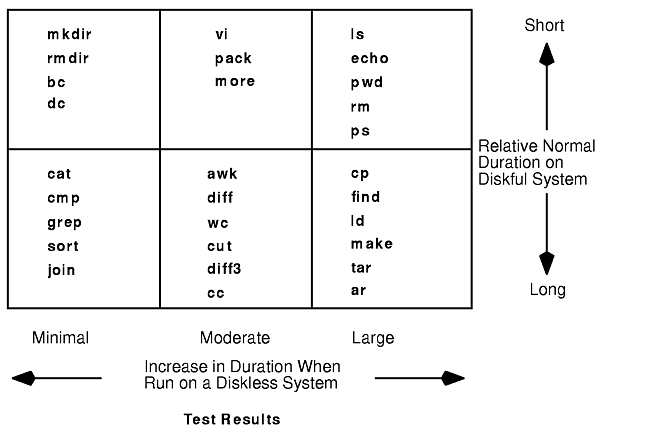
AIX commands experience the same kinds of behavior we observed when running a trivial program (see "When a Program Runs on a Diskless Workstation"). The behavior of commands can be predicted based on the type and number of file-system operations required in their execution. Commands that do numerous file lookup operations, such as find, or lots of read and/or write operations, such as a large cp, will run much slower on a diskless system. The figure "Test Results" should give you a sense of the diskless performance of some frequently used commands.
The penalty experienced by a command on a diskless client is expressed as a ratio of elapsed time diskful to elapsed time diskless. This ratio is interesting, but not always important. For example, if a command executes in 0.05 seconds diskful and 0.2 seconds diskless, the diskless penalty is four. But does an end user care? The 0.2 second response is well within human tolerance. On the other hand, if the command is used in a shell script and executed 100 times, the shell script response time might increase from 5 seconds to 20 seconds. For this reason, a good rule of thumb is to avoid diskless workstations for users who have complex, frequently executed shell scripts.
As an example of client I/O characteristics, we measured a workload that is representative of a single-user-per-client office environment on a 16MB diskless RS/6000 Model 220. The workload creates a file, using the vi editor, at a typing rate of 6 characters per second. nroff, spell, and cat utilities are run against the document. The document is tftped to the server. Additional commands include cal, calendar, rm, mail, and a small program to do telephone number lookup. Simulated "think time" is included between commands.
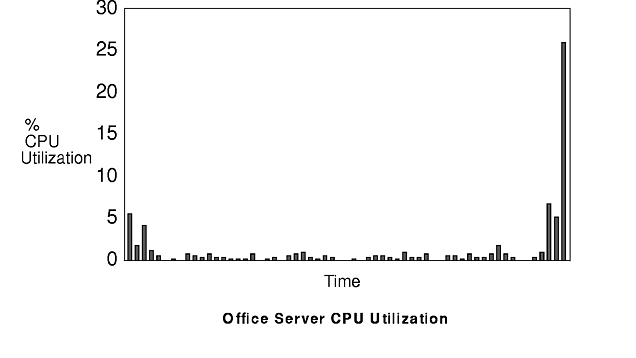
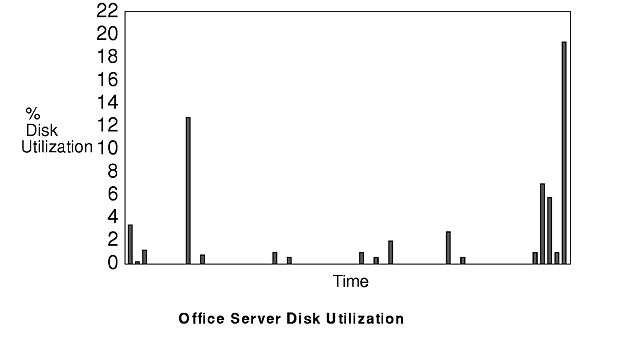
The figure "Office Server CPU Utilization" and the figure "Office Server Disk Utilization" show server-CPU and server-disk resource utilization for the office workload. The server is a Model 530H with a single 857MB hard disk. The client running the office workload is a single Model 220. The workload is "bursty"--the peaks of utilization are much higher than the average utilization.
The figure "Office Ethernet Packets/Second" shows the I/O-request pattern on the Ethernet over the period of the workload execution. The average NFS request count is 9.5 requests/second, with a peak of 249 requests/second. The figure "Office Ethernet Bytes/second" shows the total bytes transferred per second, including protocol overhead. The average transfer rate is 4000 bytes/second, with a peak of 114,341 bytes/second. This workload consumes an average of 1/300th of the nominal bandwidth of an Ethernet, with a peak of 1/11 utilization.
Since the average per-client server-CPU utilization is 2%, the average server-disk utilization per client is 2.8%, and the average Ethernet utilization is 0.3%, the disk will probably be the critical resource when a number of copies of this workload are using a single server.
As another example of client-I/O characteristics, we measured a compile/link/execute workload on a 16MB diskless RS/6000 Model 220. This is a very heavy workload compared with the office case just described. The workload combines a number of AIX services commonly used in software development in a single-user-per-client environment. Simulated "think time" is included to mimic typing delays.
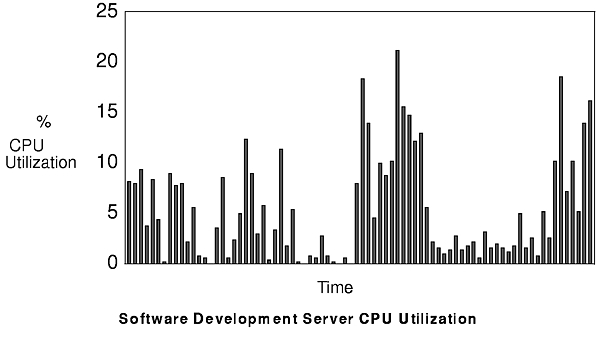
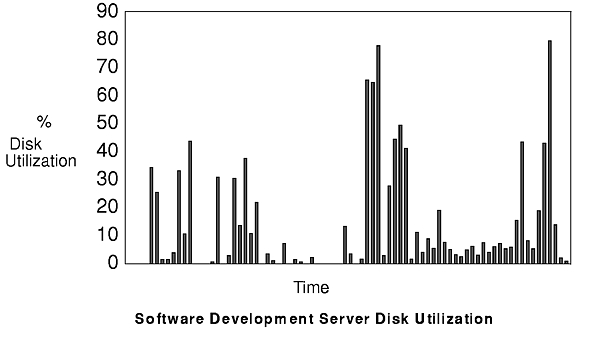
The figures "Software Development Server CPU Utilization" and "Software Development Server Disk Utilization" show the server-resource utilization for this workload. The same configuration as the previous case study was used.
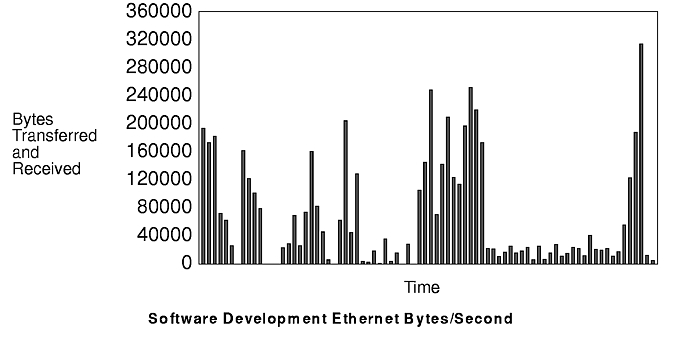
The figure "Software Development Ethernet Packets/Second" shows the I/O request pattern on the Ethernet over the period of the workload execution. The average NFS request count is 82 requests/second, with a peak of 364 requests/second. The figure "Software Development Ethernet Bytes/Second" shows the total bytes transferred per second, including protocol overhead. The average transfer rate is 67,540 bytes/second, with a peak of 314,750 bytes/second. This workload consumes an average of 1/18th of the nominal bandwidth of an Ethernet, with a peak of 1/4 utilization.
Since the average per-client server-CPU utilization is 4.2%, the average server-disk utilization per client is 8.9%, and the average Ethernet utilization is 5.3%, the disk will probably be the critical resource when a number of copies of this workload are using a single server. However, if a second disk were added to the server configuration, the Ethernet would probably be the next resource to saturate. There's always a "next bottleneck."
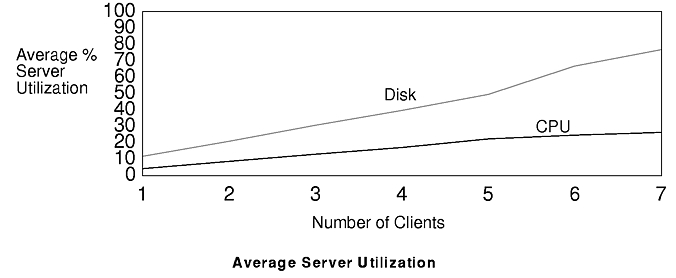
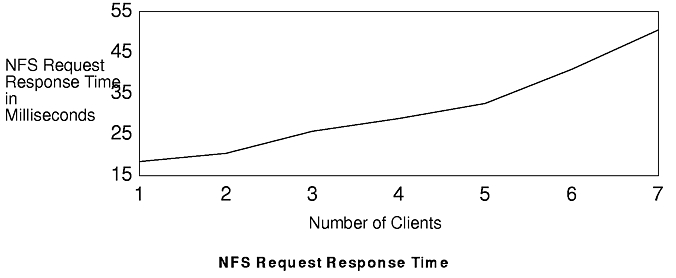
Given that the disk bottleneck occurs at a small number of clients for this workload, it is easily measured. The figure "Average Server Utilization" shows the average CPU utilization and average disk utilization (one-disk server) of the server as clients are added. The figure "NFS Request Response Time" shows the measured response time for NFS requests as the number of clients is increased.
The iostat, nfsstat, rm, and smit commands
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}